Tutorial Programación C++
HERENCIA Y POLIMORFISMO
Hasta ahora hemos visto como definir clases en C++ y una serie de características de estas últimas, como la forma de crear objetos, de declarar miembros con distintos tipos de acceso, etcétera. Pero todas estas características son tan sólo una parte de la historia. Dijimos que el uso de objetos se introducía para representar conceptos del mundo de nuestro programa en una forma cómoda y que permitían el uso de las clases como tipos del lenguaje, pero, ¿cómo representamos las relaciones entre los objetos?, es decir, ¿cómo indicamos la relación entre las personas y los empleados, por ejemplo?.
Esto se consigue definiendo una serie de relaciones de parentesco entre las clases. Definimos las clases como antes, pero intentamos dar unas clases base o clases padre para representar las características comunes de las clases y luego definimos unas clases derivadas o subclases que definen tan sólo las características diferenciadoras de los objetos de esa clase. Por ejemplo, si queremos representar empleados y clientes podemos definir una clase base persona que contenga las características comunes de ambas clases (nombre, DNI, etc.) y después declararemos las clases empleado y cliente como derivadas de persona, y sólo definiremos los miembros que son nuevos respecto a las personas o los que tienen características diferentes en la clase derivada, por ejemplo un empleado puede ser despedido, tiene un sueldo, puede firmar un contrato, etc., mientras que un cliente puede tener una cuenta, una lista de pedidos, puede firmar un contrato, etc. Como se ha mencionado ambos tipos pueden firmar contratos, pero los métodos serán diferentes, ya que la acción es la misma pero tiene significados distintos.
En definitiva, introducimos los mecanismos de la herencia y polimorfismo para implementar las relaciones entre las clases. La herencia consiste en la definición de clases a partir de otras clases, de tal forma que la clase derivada hereda las características de la clase base, mientras que el polimorfismo nos permite que métodos declarados de la misma manera en una clase base y una derivada se comporten de forma distinta en función de la clase del objeto que la invoque, el método es polimórfico, tiene varias formas.
Clases derivadas o subclases
Clases derivadas
Una clase derivada es una clase que se define en función de otra clase. La sintaxis es muy simple, declaramos la clase como siempre, pero después de nombrar la clase escribimos dos puntos y el nombre de su clase base. Esto le indica al compilador que todos los miembros de la clase base se heredan en la nueva clase. Por ejemplo, si tenemos la clase empleado (derivada de persona ) y queremos definir la clase directivo podemos declarar esta última como derivada de la primera. Así, un directivo tendrá las características de persona y de empleado , pero definirá además unos nuevos atributos y métodos propios de su clase:
class directivo : empleado {
private:
long num_empleados;
long num_acciones;
...
public:
...
void despide_a (empleado *e);
void reunion_con (directivo *d);
...
};
directivo d1, d2;
empleado e1;
lista_empleados *le;
le= &d 1; // inserta un directivo en la lista de empleados
d1.next = &e 1; // el siguiente empleado es e1
e1.next = &d 2; // el siguiente empleado es el directivo 2
d1.despide_a (&e1); // el directivo puede despedir a un empleado
d1.despide_a (&d2); // o a otro directivo, ya que también es un empleado
e1.despide_a (&d1); // ERROR, un empleado no tiene definido el método despide a
d1.reunion_con (&d2); // Un directivo se reúne con otro
d1.reunion_con (&e); // ERROR, un empleado no se reúne con un directivo
empleado *e2 = &d 2; // CORRECTO, un directivo es un empleado
directivo *d3 = & e; // ERROR, no todos los empleados son directivos
d3->num_empleados =3; // Puede provocar un error, ya que e1 no tiene espacio
reservado para num_empleados
d3 = (directivo *)e2. // CORRECTO, e2 apunta a un directivo
d3->num_empleados =3; // CORRECTO, d3 apunta a un directivo
Funciones miembro en clases derivadas
En el ejemplo del punto anterior hemos definido nuevos miembros (podemos definir nuevos atributos y métodos, e incluso atributos de la clase derivada con los mismos nombres que atributos de la clase base de igual o distinto tipo) para la clase derivada, pero, ¿cómo accedemos a los miembros de la clase base desde la derivada? Si no se redefinen podemos acceder a los atributos de la forma habitual y llamar a los métodos como si estuvieran definidos en la clase derivada, pero si se redefinen para acceder al miembro de la clase base debemos emplear el operador de campo aplicado al nombre de la clase base (en caso contrario accedemos al miembro de la clase derivada):
class empleado {
...
void imprime_sueldo();
void imprime_ficha ();
...
}
class directivo : empleado {
...
void imprime_ficha () {
imprime_sueldo();
empleado::imprime_ficha();
...
}
...
};
directivo d;
d.imprime_sueldo (); // se llama al método implementado para empleado, ya que la clase directivo no define el método
d.imprime_ficha (); // se llama al método definido en directivo
d.empleado::imprime_ficha (); // llamamos al método de la clase base empleado
Algunas clases derivadas necesitan constructores, y si la clase base de una clase derivada tiene un constructor este debe ser llamado proporcionándole los parámetros que necesite. En realidad, la gestión de las llamadas a los constructores de una clase base se gestionan igual que cuando definimos objetos miembro, es decir, se llaman en el constructor de la clase derivada de forma implícita si no ponemos nada (cuando la clase base tiene un constructor por defecto) o de forma explícita siempre que queramos llamar a un constructor con parámetros (o cuando esto es necesario). La única diferencia con la llamada al constructor respecto al caso de los objetos miembro es que en este caso llamamos al constructor con el nombre de la clase y no del objeto, ya que aquí no existe.
Veamos un ejemplo:
class X {
...
X(); // constructor sin param
X (int); // constructor que recibe un entero
~X(); // destructor
};
class Y : X {
...
Y(); // constructor sin param
Y(int); // constructor con un parámetro entero
Y (int, int); // constructor con dos parámetros enteros
...
};
// constructor sin param, invoca al constructor por defecto de X
Y::Y() {
...
}
// constructor con un parámetro entero, invoca al constructor que recibe un entero
// de la clase X
Y::Y(int i) : X(i)
{
...
}
// constructor con dos parámetros enteros, invoca al constructor por defecto de X
Y::Y (int i , int j)
{
...
}
Como ya hemos visto las clases derivadas pueden a su vez ser clases base de otras clases, por lo que es lógico pensar que las aplicaciones en las que definamos varias clases acabemos teniendo una estructura en árbol de clases y subclases. En realidad esto es lo habitual, construir una jerarquía de clases en las que la clase base es el tipo objeto y a partir de él cuelgan todas las clases. Esta estructura tiene la ventaja de que podemos aplicar determinadas operaciones sobre todos los objetos de la clase, como por ejemplo mantener una estructura de punteros a objeto de todos los objetos dinámicos de nuestro programa o declarar una serie de variables globales en la clase raíz de nuestra jerarquía que sean accesibles para todas las clases pero no para funciones definidas fuera de las clases.
A parte de el diseño en árbol se utiliza también la estructura de bosque: definimos una serie de clases sin descendencia común, pero que crean sus propios árboles de clases. Generalmente se utiliza un árbol principal y luego una serie de clases contenedor que no están en la jerarquía principal y por tanto pueden almacenar objetos de cualquier tipo sin pertenecer realmente a la jerarquía (si están junto con el árbol principal podemos llegar a hacer programas muy complejos de forma innecesaria, ya que una pila podría almacenarse a sí misma, causando problemas a la hora de destruir objetos).
Por último mencionaremos que no siempre la estructura es un árbol, ya que la idea de herencia múltiple provoca la posibilidad de interdependencia entre nodos de ramas distintas, por lo que sería más correcto hablar de grafos en vez de árboles.
Los métodos virtuales
El C++ permite el empleo de funciones polimórficas, que son aquellas que se declaran de la misma manera en distintas clases y se definen de forma diferente. En función del objeto que invoque a una función polimórfica se utilizará una función u otra. En definitiva, una función polimórfica será aquella que tendrá formas distintas según el objeto que la emplee.
Los métodos virtuales son un mecanismo proporcionado por el C++ que nos permiten declarar funciones polimórficas. Cuando definimos un objeto de una clase e invocamos a una función virtual el compilador llamará a la función correspondiente a la de la clase del objeto.
Para declarar una función como virtual basta poner la palabra virtual antes de la declaración de la función en la declaración de la clase.
Una función declarada como virtual debe ser definida en la clase base que la declara (excepto si la función es virtual pura), y podrá ser empleada aunque no haya ninguna clase derivada. Las funciones virtuales sólo se redefinen cuando una clase derivada necesita modificar la de su clase base.
Una vez se declara un método como virtual esa función sigue siéndolo en todas las clases derivadas que lo definen, aunque no lo indiquemos. Es recomendable poner siempre que la función es virtual, ya que si tenemos una jerarquía grande se nos puede olvidar que la función fue declarada como virtual.
Para gestionar las funciones virtuales el compilador crea una tabla de punteros a función para las funciones virtuales de la clase, y luego cada objeto de esa clase contendrá un puntero a dicha tabla. De esta manera tenemos dos niveles de indirección, pero el acceso es rápido y el incremento de memoria escaso. Al emplear el puntero a la tabla el compilador utiliza la función asociada al objeto, no la función de la clase que tenga el objeto en el momento de invocarla. Empleando funciones virtuales nos aseguramos que los objetos de una clase usarán sus propias funciones virtuales aunque se estén accediendo a través de punteros a objetos de un tipo base.
Ejemplo:
class empleado {
...
virtual void imprime_sueldo() const;
virtual void imprime_ficha () const;
...
}
class directivo : empleado {
...
virtual void imprime_ficha () const;
...
};
// no es necesario poner virtual
directivo d;
empleado e;
d.imprime_ficha (); // llamamos a la función de directivo
e.imprime_ficha (); // llamamos a la función de empleado
d.imprime_sueldo(); // llamamos a la función de empleado, ya que aunque es
virtual, la clase directivo no la redefine
empleado *pe = & d;
pe->imprime_sueldo(); // pe apunta a un directivo, llamamos a la función de la clase directivo, que es la asociada al objeto d
Los destructores si pueden ser declarados virtuales.
Las funciones virtuales necesitan el parámetro this para saber que objeto las utiliza y por tanto no pueden ser declaradas static ni friend . Una función friend no es un método de la clase que la declara como amiga, por lo que tampoco tendría sentido definirla como virtual . De cualquier forma dijimos que una clase puede tener como amigos métodos de otras clases. Pues bien, estos métodos amigos pueden ser virtuales, si nos fijamos un poco, la clase que declara una función como amiga no tiene porque saber si esta es virtual o no.
Clases abstractas
Ya hemos mencionado lo que son las jerarquías de clases, pero hemos dicho que se pueden declarar objetos de cualquiera de las clases de la jerarquía. Esto tienen un problema importante, al definir una jerarquía es habitual definir clases que no queremos que se puedan instanciar, es decir, clases que sólo sirven para definir el tipo de atributos y mensajes comunes para sus clases derivadas: son las denominadas clases abstractas.
En estas clases es típico definir métodos virtuales sin implementar, es decir, métodos que dicen como debe ser el mensaje pero no qué se debe hacer cuando se emplean con objetos del tipo base. Este mecanismo nos obliga a implementar estos métodos en todas las clases derivadas, haciendo más fácil la consistencia de las clases.
Pues bien, el C++ define un mecanismo para hacer esto (ya que si no lo hiciera deberíamos definir esos métodos virtuales con un código vacío, lo que no impediría que declaráramos subclases que no definieran el método y además permitiría que definiéramos objetos del tipo base abstracto).
La idea es que podemos definir uno o varios métodos como virtuales puros o abstractos (sin implementación), y esto nos obliga a redeclararlos en todas las clases derivadas (siempre que queramos definir objetos de estas subclases). Además, una clase con métodos abstractos se considera una clase abstracta y por tanto no podemos definir objetos de esa clase.
Para declarar un método como abstracto sólo tenemos que igualarlo a cero en la declaración de la clase (escribimos un igual a cero después del prototipo del método, justo antes del punto y coma, como cuando inicializamos variables):
class X {
private:
...
public:
X();
~X();
virtual void f(int) = 0; // método abstracto, no debemos definir la función para esta clase
...
}
class Y : public X {
...
virtual void f(int); // volvemos a declarar f, deberemos definir el método para la clase Y
...
}
Una subclase de una clase abstracta será abstracta siempre que no redefinamos todas las funciones virtuales puras de la clase padre. Si redefinimos algunas de ellas, las clases que deriven de la subclase abstracta sólo necesitarán implementar las funciones virtuales puras que su clase padre (la derivada de la abstracta original) no haya definido.
Herencia múltiple
La idea de la herencia múltiple es bastante simple, aunque tiene algunos problemas a nivel de uso. Igual que decíamos que una clase podía heredar características de otra, se nos puede ocurrir que una clase podría heredar características de más de una clase. El ejemplo típico es la definición de la clase de vehículos anfibios, como sabemos los anfibios son vehículos que pueden circular por tierra o por mar. Por tanto, podríamos definir los anfibios como elementos que heredan características de los vehículos terrestres y los vehículos marinos.
La sintaxis para expresar que una clase deriva de más de una clase base es simple, ponemos el nombre de la nueva clase, dos puntos y la lista de clases padre:
class anfibio : terrestre, marino {
...
};
Todo lo que hemos comentado hasta ahora es que la herencia múltiple es como la simple, excepto por el hecho de que tomamos (heredamos) características de dos clases. Pero no todo es tan sencillo, existen una serie de problemas que comentaremos en los puntos siguientes.
Ocurrencias múltiples de una base
Con la posibilidad de que una clase derive de varias clases es fácil que se presente el caso de que una clase tenga una clase como clase más de una vez. Por ejemplo en el caso del anfibio tenemos como base las clases terrestre y marino, pero ambas clases podrían derivar de una misma clase base vehículo. Esto no tiene porque crear problemas, ya que podemos considerar que los objetos de la clase anfibio contienen objetos de las clases terrestre y marino, que a su vez contienen objetos diferentes de la clase vehículo. De todas formas, si intentamos acceder a miembros de la clase vehículo, aparecerán ambigüedades. A continuación veremos como podemos resolverlas.
Resolución de ambigüedades
Evidentemente, dos clases pueden tener miembros con el mismo nombre, pero cuando trabajamos con herencia múltiple esto puede crear ambigüedades que deben ser resueltas. El método para acceder a miembros con el mismo nombre en dos clases base desde una clase derivada es emplear el operador de campo, indicando cuál es la clase del miembro al que accedemos:
class terrestre : vehiculo {
...
char *Tipo_Motor;
...
virtual void imprime_tipo_motor() { cout << Tipo_Motor; }
...
};
class marino : vehiculo {
...
char *Tipo_Motor;
...
virtual void imprime_tipo_motor(); { cout << Tipo_Motor; }
...
};
class anfibio : terrestre, marino {
...
virtual void imprime_tipo_motor();
...
};
void anfibio::imprime_tipo_motor () {
cout << "Motor terrestre : ";
terrestre::imprime_tipo_motor ();
cout << "Motor acuático : ";
marino::imprime_tipo_motor ();
}
Si intentamos acceder a miembros ambiguos el compilador no generará código hasta que resolvamos la ambigüedad.
Clases base virtuales
Las clases base que hemos empleado hasta ahora con herencia múltiple tienen la suficiente entidad como para que se declararen objetos de esas clases, es decir, heredábamos de dos o más clases porque en realidad los objetos de la nueva clase se componían o formaban a partir de otros objetos. Esto está muy bien, y suele ser lo habitual, pero existe otra forma de emplear la herencia múltiple: el hermanado de clases.
El mecanismo de hermanado se basa en lo siguiente: para definir clases que toman varias características de clases derivadas de una misma clase. Es decir, definimos una clase base y derivamos clases que le añaden características y luego queremos usar objetos que tengan varias de las características que nos han originado clases derivadas. En lugar de derivar una clase de la base que reúna las características, podemos derivar una clase de las subclases que las incorporen. Por ejemplo, si definimos una clase ventana y derivamos las clases ventana_con_borde y ventana_con_menu, en lugar de derivar de la clase ventana una clase ventana_con_menu_y_borde, la derivamos de las dos subclases. En realidad lo que queremos es emplear un mismo objeto de la clase base ventana, por lo que nos interesa que las dos subclases generen sus objetos a partir de un mismo objeto ventana. Esto se consigue declarando la herencia de la clase base como virtual en todas las subclases que quieran compartir su padre con otras subclases al ser empleadas como clase base, y también en las subclases que la hereden desde varias clases distintas:
class ventana {
};
class ventana_con_borde : public virtual ventana {
};
class ventana_con_menu
};
: public virtual ventana {
class ventana_con_menu_y_borde
: public virtual ventana,
public ventana_con_borde,
public ventana_con_menu {
};
Por ejemplo, en el caso de la clase ventana, supongamos que definimos un método dibujar, que es invocado por los métodos dibujar de las clases ventana_con_borde y ventana_con_menu. Para definir el método dibujar de la nueva clase ventana_con_menu_y_borde lo lógico sería llamar a los métodos de sus funciones padre, pero esto provocaría que llamáramos dos veces al método dibujar de la clase ventana, provocando no sólo ineficiencia, sino incluso errores (ya que el redibujado de la ventana puede borrar algo que no debe borrar, por ejemplo el menú). La solución pasaría por definir dos funciones de dibujo, una virtual y otra no virtual, usaremos la virtual para dibujar objetos de la clase (por ejemplo ventanas con marco) y la no virtual para dibujar sólo lo característico de nuestra clase. Al definir la clase que agrupa características llamaremos a las funciones no virtuales de las clases padre, evitando que se repitan llamadas.
Otro problema con estas clases es que si dos funciones hermanas redefinen un método de la clase padre (como el método dibujar anterior), la clase que herede de ambas deberá redefinirla para evitar ambigüedades (¿a qué función se llama si la subclase no redefine el método?).
Necesidad de la herencia múltiple
Como hemos visto, la herencia múltiple le da mucha potencia al C++, pero por otro lado introduce una gran complejidad a la hora de definir las clases derivadas de más de una clase. En realidad no existe (que yo sepa), ninguna cosa que se pueda hacer con herencia múltiple que no se pueda hacer con herencia simple escribiendo más código.
Ha habido muchas discusiones por culpa de la incorporación de esta característica al C++, ya que complica mucho la escritura de los compiladores, pero como se ha incorporado al estándar, lo lógico es que todos los compiladores escritos a partir del estándar la incorporen. Por tanto, el uso o no de la herencia múltiple depende de las ventajas que nos reporte a la hora de hacer un programa. Lo más normal es que ni tan siquiera lleguéis a utilizarla.
Control de acceso
Como ya comentamos en puntos anteriores, los miembros de una clase pueden ser privados, protegidos o públicos ( private, protected , public ). El acceso a los miembros privados está limitado a funciones miembro y amigas de la clase, el acceso protegido es igual que el privado, pero también permite que accedan a ellos las clases derivadas y los miembros públicos son accesibles desde cualquier sitio en el que la clase sea accesible.
El único modelo de acceso que no hemos estudiado es el protegido. Cuando implementamos una clase base podemos querer definir funciones que puedan utilizar las clases derivadas pero que no se puedan usar desde fuera de la clase. Si definimos miembros como privados tenemos el problema de que la clase derivada tampoco puede acceder a ellos. La solución es definir esos métodos como protected .
Estos niveles de acceso reflejan los tipos de funciones que acceden a las clases: las funciones que la implementan, las que implementan clases derivadas y el resto.
Ya se ha mencionado que dentro de la clase podemos definir prácticamente cualquier cosa (tipos, variables, funciones, constantes, etc.). El nivel de acceso se aplica a los nombres, por lo que lo que podemos definir como privados, públicos o protegidos no sólo los atributos, sino todo lo que puede formar parte de la clase.
Aunque los miembros de una clase tienen definido un nivel de acceso, también podemos especificar un nivel de acceso a las clases base desde clases derivadas. El nivel de acceso a clases base se emplea para saber quien puede convertir punteros a la clase derivada en punteros a la clase base (de forma implícita, ya que con casts siempre se puede) y acceder a miembros de la clase base heredados en la derivada. Es decir, una clase con acceso private a su clase base puede acceder a su clase base, pero ni sus clases derivadas ni otras funciones tienen acceso a la misma, es como si definiéramos todos los miembros de la clase base como private en la clase derivada. Si el acceso a la clase base es protected , sólo los miembros de la clase derivada y los de las clases derivadas de esta última tienen acceso a la clase base. Y si el acceso es público, el acceso a los miembros de la clase base es el especificado en ella.
Para especificar el nivel de acceso a la clase base ponemos la etiqueta de nivel de acceso antes de escribir su nombre en la definición de una clase derivada. Si la clase tiene herencia múltiple, debemos especificar el acceso de todas las clases base. Si no ponemos nada, el acceso a las clases base se asume public .
Ejemplo:
class anfibio : public terrestre, protected marino {
...
};
Cuando creamos objetos de una clase derivada se llama a los constructores de sus clases base antes de ejecutar el de la clase, y luego se ejecuta el suyo. El orden de llamada a los destructores es el inverso, primero el de la clase derivada y luego el de sus padres.
Comentamos al hablar de métodos virtuales que los destructores podían ser declarados como tales, la utilidad de esto es clara: si queremos destruir un objeto de una clase derivada usando un puntero a una clase base y el destructor no es virtual la destrucción será errónea, con los problemas que esto puede traer. De hecho casi todos los compiladores definen un flag para que los destructores sean virtuales por defecto. Lo más típico es declarar los destructores como virtuales siempre que en una clase se defina un método virtual, ya que es muy posible que se manejen punteros a objetos de esa clase.
Además de comentar la forma de llamar a constructores y destructores, en este punto se podría hablar de las posibilidades de sobrecarga de los operadores new y delete para clases, ya que esta sobrecarga nos permite modificar el modo en que se gestiona la memoria al crear objetos. Como el siguiente punto es la sobrecarga de operadores estudiaremos esta posibilidad en ella. Sólo decir que la sobrecarga de la gestión de memoria es especialmente interesante en las clases base, ya que si ahorramos memoria al trabajar con objetos de la clase base es evidente que la ahorraremos siempre que creemos objetos de clases derivadas.
SOBRECARGA DE OPERADORES
Ya hemos mencionado que el C++ permite la sobrecarga de operadores. Esta capacidad se traduce en poder definir un significado para los operadores cuando los aplicamos a objetos de una clase específica. Además de los operadores aritméticos, lógicos y relacionales, también la llamada () , el subíndice [] y la dereferencia -> se pueden definir, e incluso la asignación y la inicialización pueden redefinirse. También es posible definir la conversión implícita y explícita de tipos entre clases de usuario y tipos del lenguaje.
Funciones operador
Se pueden declarar funciones para definir significados para los siguientes operadores:
+ = | = || - < << ++ * > >> -- / += <<= ->* % -= >>= , ^ *= == -> & /= != [] | %= <= () ~ ^= >= new ! &= && delete
No podemos modificar ni las precedencias ni la sintaxis de las expresiones para los operadores, ya que podríamos provocar ambigüedades. Tampoco podemos definir nuevos operadores.
El nombre de una función operador es la palabra clave operator seguida del operador, por ejemplo operator+ . Al emplear un operador podemos llamar a su función o poner el operador, el uso del operador sólo es para simplificar la escritura. Por ejemplo:
int c = a + b;
int c = operator+ (a, b);
En C++ tenemos operadores binarios (con dos operandos) y unarios (con un operando).
Los operadores binarios se pueden definir como una función miembro con un argumento (el otro será el objeto de la clase que lo emplee) o como funciones globales con dos argumentos. De esta forma, para cualquier operador binario @ , a@b se interpretará como o como . Si las dos funciones están definidas, se aplican una serie de reglas para saber que función utilizar (si es posible decidirlo).
Los operadores unarios, ya sean prefijos o postfijos, se pueden definir como función miembro sin argumentos o como función global con un argumento. Igual que para operadores binarios, si definimos un operador de las dos formas habrá que determinar según unas reglas que operador emplear.
Veremos al hablar del incremento y decremento como se trabaja con operadores prefijos y postfijos.
Los operadores sólo se pueden definir del tipo (unario o binario) que tienen en C++, no podemos usar operadores binarios como unarios ni viceversa y no podemos definir operadores con más de 2 operandos.
Significados predefinidos de los operadores
Sobre los operadores definidos por el usuario sólo se hacen algunas consideraciones, en particular los operadores operator= , operator[] , operator() y operator-> no pueden ser funciones miembro estáticas (esto asegura que sus primeros operandos serán LValues).
Los significados de algunos operadores predefinidos por el lenguaje están relacionados, pero esto no implica que cuando redefinamos un operador los relacionados con él mantengan esta relación. Por ejemplo, el operador += y el operador + están relacionados, pero redefiniendo + no hacemos que += emplee la nueva suma antes de la asignación. Si quisiéramos que esto fuera así deberíamos redefinir también el operador += .
Operadores y clases
Todos los operadores sobrecargados deben ser miembros de una clase o tener como argumento un objeto de una clase (excepto para los operadores new y delete ). En particular, no pueden definirse operadores que operen exclusivamente con punteros. Esto sirve para asegurar que los significados predefinidos del C++ no se pueden alterar (una expresión no puede modificar su significado a menos que intervengan objetos de clases definidas por el usuario).
Un operador que acepte como primer operando un tipo básico no puede ser una función miembro, ya que no podríamos interpretar el operador como miembro de una clase, puesto que no existe la definición de clase para los tipos básicos.
Una cosa importante a este respecto es tener en cuenta que la definición de un operador no es conmutativa, es decir, si queremos aplicar un operador al tipo A y al tipo B en ambos sentidos debemos definir dos funciones para cada operación.
Conversiones de tipos
Cuando queremos definir una serie de operadores para trabajar con una clase tenemos que redefinir cada operación para emplearla con los objetos de esa clase y después redefinirla también para todas las operaciones con otros tipos (y además en ambos sentidos, para operadores conmutativos). Para evitar tener que definir las funciones que operan con objetos de nuestra clase y objetos de otras clases podemos emplear un truco bastante simple: definimos un conversor de los tipos para pasar objetos de otros tipos a objetos de nuestra clase.
Uso de constructores
Un tipo de conversión de tipos es la realizada mediante constructores que aceptan como parámetro un objeto de un tipo y crean un objeto de nuestra clase usando el objeto parámetro. Por ejemplo, si tenemos un tipo complejo con la siguiente definición:
class complejo {
private:
double re, im;
public:
complejo(double r, double i=0) {
// constructor / conversor de double a complejo
re = r; im = i;
}
// operadores como funciones amigas
friend complejo operator+ (complejo, complejo); // suma de complejos
friend complejo operator* (complejo, complejo); // producto de complejos
...
// operadores como funciones miembro
complejo operator+=(complejo); // suma y asignación
complejo operator*=(complejo); // producto y asignación
...
};
complejo z1 = complejo (23); // z1 toma el valor (23 + i*0)
complejo z2 = 23; // z2 toma el valor (23 + i*0), llamamos implícitamente al constructor
Si el operador crea objetos temporales automáticamente, los destruirá en cuanto pueda (generalmente después de emplearlos en la operación). La conversión implícita sólo se realiza si el conversor definido por el usuario es único.
Operadores de conversión
La conversión de tipos usando constructores tiene algunos problemas:
1. No puede haber conversión implícita de un objeto de una clase a un tipo básico, ya que los tipos básicos no son clases.
2. No podemos especificar la conversión de un tipo nuevo a uno viejo sin modificar la vieja clase.
3. No es posible tener un constructor sin tener además un conversor.
El último problema no es realmente grave, ya que el empleo del constructor como conversor suele tener siempre un sentido, y los dos primeros problemas se solucionan definiendo operadores de conversión para el tipo fuente.
Una función miembro X::operatorT() , donde T es el nombre de un tipo, define una conversión de X a T . Este tipo de conversiones se deben definir sólo si son realmente necesarias, si se usan poco es preferible definir una función miembro normal para hacer las conversiones, ya que hay que llamarla explícitamente y puede evitar errores no intencionados.
Problemas de ambigüedad
Una asignación o inicialización de un objeto de una clase X es legal si, o bien el valor asignado es de tipo X o sólo hay una conversión de el valor asignado al tipo X . En algunos casos una conversión necesita el uso repetido de constructores o operadores de conversión, sólo se usará conversión implícita de usuario en un primer nivel, si son necesarias varias conversiones de usuario hay que hacerlas explícitamente. Si existe más de un conversor de tipos, la conversión implícita es ilegal.
Operadores y objetos grandes
Cuando una clase define objetos pequeños, la utilización de copias de los objetos en las conversiones o en las operaciones no causa mucho problema, pero su la clase define objetos de gran tamaño, la copia puede ser excesivamente costosa (ineficiente). Para evitar el empleo de copias podemos definir los argumentos (y retornos) de una función como referencias (recordemos que los punteros no se pueden usar porque no se puede modificar el significado de un operador cuando se aplica a punteros).
Los parámetros referencia no causan ningún problema, pero los retornos referencia deben se usados con cuidado: si hay que crear el objeto resultado es preferible retornar un objeto y que se copie, ya que la gestión de memoria para retornar referencias a objetos creados en la función del operador puede resultar muy complicada.
Asignación e inicialización
La asignación entre objetos de un mismo tipo definido por el usuario puede crear problemas, por ejemplo, si tenemos la clase cadena:
class cadena {
private:
char *p; // puntero a cadena
int tam; // tamaño de la cadena apuntada por p
public:
cadena (int t) { p = new char [tam =t] }
~cadena () { delete []p; }
}
cadena c1(10);
cadena c2(20);
c2 = c1;
class cadena {
...
cadena& operator= (const cadena&); // operador de asignación
}
cadena& cadena::operator= (const cadena& a) {
if (this != &a) { // si no igualamos una cadena a si misma
delete []p;
p = new char[tam = a.tam];
strncpy (p, a.p);
}
return *this; // nos retornamos a nosotros mismos
}
cadena c1(10);
cadena c2 = c1;
class cadena {
...
cadena (const cadena&); // constructor copia
}
cadena::cadena (const cadena& a) {
p = new char[tam = a.tam];
strncpy (p, a.p);
}
El operador operator[] puede redefinirse para dar un significado a los subíndices para los objetos de una clase. Lo bueno es que el segundo operando (el subíndice) puede ser de cualquier tipo.
Para redefinir el operador de subíndice debemos definirlo como función miembro. Por ejemplo, para acceder a los elementos de un conjunto de enteros almacenado en una lista podemos redefinir el operador de subíndice:
class cjto {
private:
nodo_lista *elem;
...
public:
...
int operator[] (int);
...
}
int cjto::operator[] (int i) {
nodo_lista *n = elem; // puntero al primer elem. de la lista
for (int k=0; k< i; k++) // recorremos la lista hasta llegar al elem i
if (!(n = n->sig)) return 0; // siempre y cuando este exista
return n->val; // retornamos el contenido de la posición i
}
La llamada a función, esto es, la notación expresión(lista_expresiones) , puede ser interpretada como una operación binaria con expresión como primer argumento y lista_expresiones como segundo. La llamada operator() puede ser sobrecargada como los otros operadores. La lista de expresiones se chequea como en las llamadas a función.
La sobrecarga de la llamada a función se redefine para emplear los objetos como llamadas a función (sobre todo para definir iteradores sobre clases), la ventaja de usar objetos y no funciones está en que los objetos tienen sus propios datos para guardar información sobre la aplicación sucesiva de la función, mientras que las funciones normales no pueden hacerlo. Otro uso de la sobrecarga de la llamada a función está en su empleo como operador de subíndice, sobre todo para arrays multidimensionales.
Dereferencia
El operador de dereferencia -> puede ser considerado como un operador unario postfijo. Dada una clase:
class Ptr {
...
X* operator->();
};
Ptr p;
p->m = 7; // (p.operator->)()->m = 7;
La utilidad de esta sobrecarga está en la definición de punteros inteligentes, objetos que sirven de punteros pero que realizan alguna función cuando accedemos a un objeto a través de ellos. La posibilidad de esta sobrecarga es importante para una clase interesante de programas, la razón es que la indirección es un concepto clave, y la sobrecarga de -> proporciona una buena forma de representar la indirección en los programas.
Incremento y decremento
Los operadores de incremento y decremento son muy interesantes a la hora de sobrecargarlos por varias razones: pueden ser prefijos y postfijos, son ideales para representar los accesos a estructuras ordenadas (listas, arrays, pilas, etc.), y pueden definirse de forma que verifiquen rangos en tiempo de ejecución.
Para sobrecargar estos operadores en forma prefija hacemos lo de siempre, pero para indicar que el operador es postfijo lo definimos con un argumento entero (como el operador es unario, está claro que no se usará el parámetro, es un parámetro vacío, pero con la declaración el compilador distingue entre uso prefijo y postfijo)::
class Puntero_seguro_a_T {
T* p; // puntero a T, valor inicial del array
int tam; // tamaño vector apuntado por T
...
T* operator++ (); // Prefijo
T* operator++ (int); // Postfijo
...
};
Sobrecarga de new y delete
Al igual que el resto de operadores, los operadores operator new y operator delete se pueden sobrecargar. Esto se emplea para crear y destruir objetos de formas distintas a las habituales: reservando el espacio de forma diferente o en posiciones de memoria que no están libres en el heap, inicializando la memoria a un valor concreto, etc.
El operador new tiene un parámetro obligatorio de tipo size_t y luego podemos poner todo tipo y número de parámetros. Su retorno debe ser un puntero void . El parámetro size_t es el tamaño en bytes de la memoria a reservar, si la llamada a new es para crear un vector size_t debe ser el número de elementos por el tamaño de la clase de los objetos del array.
Es muy importante tener claro lo que hacemos cuando redefinimos la gestión de memoria, y siempre que sobrecarguemos el new o el delete tener presente que ambos operadores están relacionados y ambos deben ser sobrecargados a la vez para reservar y liberar memoria de formas extrañas.
Funciones amigas o métodos
Una pregunta importante es: ¿Cuándo debo sobrecargar un operador como miembro o como función amiga?
En general, siempre es mejor usar miembros porque no introducen nuevos nombres globales. Cuando queremos definir operandos que afectan al estado de la clase debemos definirlos como miembros o como funciones amigas que toman una referencia no constante a un objeto de la clase. Si queremos emplear conversiones implícitas para todos los operandos de una operación, la función que sobrecarga el operador deberá ser global y recibir como parámetros una referencia constante o un argumento que no sea una referencia (esto permite la conversión de constantes).
Si no hay ninguna razón que nos incline a usar una cosa u otra lo mejor es usar miembros. Son más cómodos de definir y más claros a la hora de leer el programa. Es mucho más evidente que un operador puede modificar al objeto si es un miembro que si la función que lo implementa recibe una referencia a un objeto.
TEMPLATES
Genericidad
El C++ es un lenguaje muy potente tal y como lo hemos definido hasta ahora, pero al ir incorporándole características se ha tendido a que no se perdiera eficiencia (dentro de unos márgenes) a cambio de una mayor comodidad y potencia a la hora de programar.
El C introdujo en su momento un mecanismo sencillo para facilitar la escritura de código: las macros. Una macro es una forma de representar expresiones, se trata en realidad de evitar la repetición de la escritura de código mediante el empleo de abreviaturas, sustituimos una expresión por un nombre o un nombre con aspecto de función que luego se expande y sustituye las abreviaturas por código.
El mecanismo de las macros no estaba mal, pero tenía un grave defecto: el uso y la definición de macros se hace a ciegas en lo que al compilador se refiere. El mecanismo de sustitución que nos permite definir pseudo-funciones no realiza ningún tipo de chequeos y es por tanto poco seguro. Además, la potencia de las macros es muy limitada.
Para evitar que cada vez que definamos una función o una clase tengamos que replicar código en función de los tipos que manejemos (como parámetros en funciones o como miembros y retornos y parámetros de funciones miembro en clases) el C++ introduce el concepto de funciones y clases genéricas.
Una función genérica es realmente como una plantilla de una función, lo que representa es lo que tenemos que hacer con unos datos sin especificar el tipo de algunos de ellos. Por ejemplo una función máximo se puede implementar igual para enteros, para reales o para complejos, siempre y cuando este definido el operador de relación <. Pues bien, la idea de las funciones genéricas es definir la operación de forma general, sin indicar los tipos de las variables que intervienen en la operación. Una vez dada una definición general, para usar la función con diferentes tipos de datos la llamaremos indicando el tipo (o los tipos de datos) que intervienen en ella. En realidad es como si le pasáramos a la función los tipos junto con los datos.
Al igual que sucede con las funciones, las clases contenedor son estructuras que almacenan información de un tipo determinado, lo que implica que cada clase contenedor debe ser reescrita para contener objetos de un tipo concreto. Si definimos la clase de forma general, sin considerar el tipo que tiene lo que vamos a almacenar y luego le pasamos a la clase el tipo o los tipos que le faltan para definir la estructura, ahorraremos tiempo y código al escribir nuestros programas.
Funciones genéricas
Para definir una función genérica sólo tenemos que poner delante de la función la palabra template seguida de una lista de nombres de tipos (precedidos de la palabra class) y separados por comas, entre los signos de menor y mayor. Los nombres de los tipos no se deben referir a tipos existentes, sino que deben ser como los nombres de las variables, identificadores.
Los tipos definidos entre mayor y menor se utilizan dentro de la clase como si de tipos de datos normales se tratara. Al llamar a la función el compilador sustituirá los tipos parametrizados en función de los parámetros actuales (por eso, todos los tipos parametrizados deben aparecer al menos una vez en la lista de parámetros de la función).
Ejemplo:
template
T max (T a, T b) { return (a>b) ? a : b } // función genérica máximo
Los tipos parámetro no sólo se pueden usar para especificar tipos de variables o de retornos, también podemos usarlos dentro de la función para lo que queramos (definir variables, punteros, asignar memoria dinámica, etc.). En definitiva, los podemos usar para lo mismo que los tipos normales.
Todos lo modificadores de una función ( inline , static , etc.) van después de template < ... > .
Las funciones genéricas se pueden sobrecargar y también especializar. Para sobrecargar una función genérica lo único que debemos hacer es redefinirla con distinto tipo de parámetros (haremos que emplee más tipos o que tome distinto número o en distinto orden los parámetros), y para especializar una función debemos implementarla con los tipos parámetro especificados (algunos de ellos al menos):
template
T max (T a, T b) { ... } // función máximo para dos parámetros de tipo T
// sobrecarga de la función
template
T max (int *p, T a) { ... } // función máximo para punteros a entero y valores de tipo T
// sobrecarga de la función
template
T max (T a[]) { ... } // función genérica máximo para vectores de tipo T
// especialización
// función máximo para cadenas como punteros a carácter
const char* max(const char *c1, const char *c2) {
return (strncmp(c1, c2) >=1) ? c1 : c2;
}
// ejemplos de uso
int i1 = 9, i2 = 12;
cout << max (i1, i2); // se llama a máximo con dos enteros, T=int
int *p = &i 2;
cout << max (p, i1); //llamamos a la función que recibe puntero y tipo T (T=entero)
cout << max ("HOLA", "ADIOS"); // se llama a la función especializada para trabajar con cadenas.
Clases genéricas
También podemos definir clases genéricas de una forma muy similar a las funciones. Esto es especialmente útil para definir las clases contenedor, ya que los tipos que contienen sólo nos interesan para almacenarlos y podemos definir las estructuras de una forma más o menos genérica sin ningún problema. Hay que indicar que si las clases necesitan comparar u operar de alguna forma con los objetos de la clase parámetro, las clases que usemos como parámetros actuales de la clase deberán tener sobrecargados los operadores que necesitemos.
Para declarar una clase paramétrica hacemos lo mismo de antes:
template
class vector {
T* v; // puntero a tipo T
int tam;
public:
vector (int);
T& operator[] (int); // el operador devuelve objetos de tipo T
...
}
vector
Una vez declarados los objetos se usan como los de una clase normal.
Para definir los métodos de la clase sólo debemos poner la palabra template con la lista de tipos y al poner el nombre de la clase adjuntarle su lista de identificadores de tipo (igual que lo que ponemos en template pero sin poner class):
template
vector
...
}
template
T& vector
...
}
...
// especializamos la clase para char *, podemos modificar totalmente la def. de la clase
class vector
char *feo;
public:
vector ();
void hola ();
}
// Si sólo queremos especializar un método, lo declaramos como siempre pero con el
// tipo para el que especializamos indicado
vector
... // constructor especial para float
}
template
class pila {
T bloque[SZ]; // vector de SZ elementos de tipo T
...
};
Otra facilidad es la de poder emplear la herencia con clases parametrizadas, tanto para definir nuevas clases genéricas como para definir clases no genéricas. En ambos casos debemos indicar los tipos de la clase base, aunque para clases genéricas derivadas de clases genéricas podemos emplear tipos de nuestra lista de parámetros.
Ejemplo:
template
class pila {
...
}
// clase template derivada
template
class pilita : public pila
...
};
// clase no template derivada
class pilita_chars : public pila
...
};
Programación y errores
Existen varios tipos de errores a la hora de programar: los errores sintácticos y los errores de uso de funciones o clase y los errores del usuario del programa. Los primeros los debe detectar el compilador, pero el resto se deben detectar en tiempo de ejecución, es decir, debemos tener código para detectarlos y tomar las acciones oportunas. Ejemplos típicos de errores son el salirse del rango de un vector, divisiones por cero, desbordamiento de la pila, etc.
Para facilitarnos el manejo de estos errores el C++ incorpora un mecanismo de tratamiento de errores más potente que el simple uso de códigos de error y funciones para tratarlos.
Tratamiento de excepciones en C++ (throw - catch - try)
La idea es la siguiente: en una cadena de llamadas a funciones los errores no se suelen tratar donde se producen, por lo que la idea es lanzar un mensaje de error desde el sitio donde se produce uno y ir pasándolo hasta que alguien se encargue de él. Si una función llama a otra y la función llamada detecta un error lo lanza y termina. La función llamante recibirá el error, si no lo trata, lo pasará a la función que la ha llamado a ella. Si la función recoge la excepción ejecuta una función de tratamiento del error. Además de poder lanzar y recibir errores, debemos definir un bloque como aceptor de errores. La idea es que probamos a ejecutar un bloque y si se producen errores los recogemos. En el resto de bloques del programa no se podrán recoger errores.
Lanzamiento de excepciones: throw
Si dentro de una función detectamos un error lanzamos una excepción poniendo la palabra throw y un parámetro de un tipo determinado, es como si ejecutáramos un return de un objeto (una cadena, un entero o una clase definida por nosotros).
Por ejemplo:
f() {
...
int *i;
if ((i= new int) == NULL)
throw "Error al reservar la memoria para i"; // no hacen falta paréntesis, es como en return
...
}
si la función f() fue invocada desde g() y esta a su vez desde h(), el error se irá pasando entre
ellas hasta que se recoja.
Para recoger un error empleamos la pseudofunción catch , esta instrucción se pone como si fuera una función, con catch y un parámetro de un tipo determinado entre paréntesis, después abrimos llave, escribimos el código de gestión del error y cerramos la llave.
Por ejemplo si la función h() trataba el error anterior:
h() {
...
catch (char *ce) {
cout << "He recibido un error que dice : " << ce;
}
...
}
h() {
...
catch (char *ce) {
... // tratamos errores que lanzan cadenas
}
catch (int ee) {
... // tratamos errores que lanzan enteros
}
...
}
h() {
...
catch (char *ce) {
... // tratamos errores que lanzan cadenas
}
catch (...) {
... // tratamos el resto de errores
}
...
}
El tratamiento de errores visto hasta ahora es muy limitado, ya que no tenemos forma de especificar donde se pueden producir errores (en que bloques del programa). La forma de especificar donde se pueden producir errores que queremos recoger es emplear bloques try , que son bloques delimitados poniendo la palabra try y luego poniendo entre llaves el código que queremos probar. Después del bloque try se ponen los bloques catch para tratar los errores que se hayan podido producir:
h() {
...
g(); // si produce un error, se le pasa al que llamo a h()
try {
g(); // si produce un error lo tratamos nosotros
}
catch (int i){
...
}
catch (...){
...
}
z();
}
Si en un bloque try se produce un error que no es tratado por sus catch , también pasamos el error hacia arriba.
Cuando se recoge un error con un catch no se retorna al sitio que lo origino, sino que se sigue con el código que hay después del último catch asociado al try donde se acepto el error. En el ejemplo se ejecutaría la función z() .
La lista throw
Podemos especificar los tipos de excepciones que puede lanzar una función, poniendo después del prototipo de la función la lista throw , que no es más que la palabra throw seguida de una lista de tipos separada por comas y entre paréntesis:
void f () throw (char*, int); // f sólo lanza cadenas y enteros
Funciones terminate() y unexpected()
Existen situaciones en las que un programa debe terminar abruptamente por que el manejo de excepciones no puede encontrar un manejador para una excepción lanzada, cuando la pila está corrompida (y no podemos ejecutar los mecanismos de excepción) o cuando un destructor llamado por una excepción provoca otra excepción.
En estos casos el programa llama automáticamente a una función llamada terminate() que no retorna nada y no tiene parámetros. Esta función llama a otra que podemos especificar nosotros mediante la llamada a una función denominada set_terminate() . Esta función acepta como parámetro punteros a funciones del tipo:
f () { // función sin parámetros que no retorna nada (ni void)
...
}
set_terminate (&f); // f() es la función que llamará terminate.
La función por defecto de terminate() es abort() que termina la ejecución sin hacer nada.
La función unexpected() se llama cuando una función lanza una excepción que no está en su lista throw , y hace lo mismo que terminate() , es decir, llama a una función. Podemos especificar a cual usando la función set_unexpected() que acepta punteros al mismo tipo de funciones que set_terminate() . La función por defecto de unexpected() es terminate() .
ENTRADA Y SALIDA
Introducción
Casi todos los lenguajes de alto nivel disponen de bibliotecas estándar de funciones para gestionar la Entrada/Salida de datos, tanto para teclado/pantalla como ficheros. El C++ no emplea esta estrategia, es decir, no define una biblioteca de funciones, sino que define una biblioteca de clases que se puede expandir y mejorar si la aplicación lo requiere.
La idea es que las operaciones de entrada y salida se aplican a objetos de unas clases determinadas, empleando la sobrecarga de operadores como método para indicar la forma de introducir y extraer datos hacia o desde la E/S a nuestro programa.
La forma de trabajar con la E/S hace que sea posible el chequeo de tipos de entrada y de salida, que tengamos una forma uniforme de leer y escribir variables de todos los tipos (incluso clases) e incluso que podamos tratar de forma similar la entrada salida para distintos dispositivos.
El concepto fundamental en C++ para tratar la entrada/salida es la noción de stream que se puede traducir como flujo o corriente. La idea es que existe un flujo de datos entre nuestro programa y el exterior, y los streams son los encargados de transportar la información, serán como un canal por el que mandamos y recibimos información.
El C++ define streams para gestionar la E/S de teclado y pantalla (entrada y salida estándar), la E/S de ficheros e incluso la gestión de E/S de cadenas de caracteres.
Primero estudiaremos la E/S entre nosotros y la máquina (teclado y pantalla) y luego veremos la gestión de ficheros y cadenas. Hablaremos primero de la entrada y la salida simples y luego comentaremos las posibilidades de formateo y el uso de los manipuladores de E/S.
Objetos Stream
El C++ define (al incluir la cabecera
cin - Objeto que recibe la entrada por teclado, pertenece a la clase istream
cout - Objeto que genera la salida por pantalla, pertenece a ostream
cerr - Objeto para salida de errores, es un ostream que inicialmente saca sus mensajes por pantalla, aunque se puede redirigir.
clog - Es igual que cerr, pero gestiona los buffers de forma diferente
Entrada y salida
En este punto describiremos la clase ios, que es la clase empleada para definir objetos de tipo stream para manejar la E/S. Primero veremos la descripción de la clase y luego veremos que cosas podemos utilizar para conocer el estado del stream, las posibilidades de formateo de E/S y una lista de funciones especiales de acceso a Streams.
La clase ios
class ios {
ostream* tie(ostream* s); // Liga dos streams // podemos ligar entrada con salida
ostream* tie();
int width(int w); // Pone la longitud de campo
int width() const; // Devuelve la longitud
char fill(char); // Pone carácter de relleno
char fill() const; // Devuelve carácter de relleno
long flags(long f); // Pone los flags del stream
long flags() const; // Devuelve los flags del stream
setf(long setbits, long field);
setf(long);
unsetf(long);
int precision(int); // Pone la precisión de los reales
int precision() const; // Devuelve la precisión de los reales
// Funciones de estado del stream
int rdstate() const;
int eof() const;
int fail() const;
int bad() const;
int good() const;
void clear(int i=0);
operator void *(); // Retorna NULL si failbit, badbit o hardfail están a uno
int operator !(); // Retorna verdadero si failbit, badbit o hardfail están a uno
};
Estado de la E/S.
enum io_state {
goodbit = OxO0, // Estado normal
eofbit = OxOl, // Al final del stream
failbit = Ox02,/* La última operación de E/S ha fallado. El stream se puede volver a usar si se recupera el error. */
badbit = Ox04, /* La última operación es inválida. El stream se puede volver a usar si se recupera el error */
hardfail = Ox08 // Error irrecuperable
};
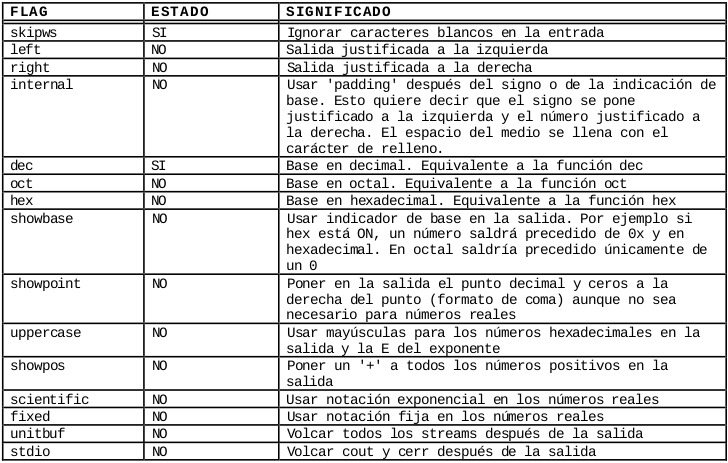
Flags
Podemos modificarlos con las funciones setf() y unsetf() .
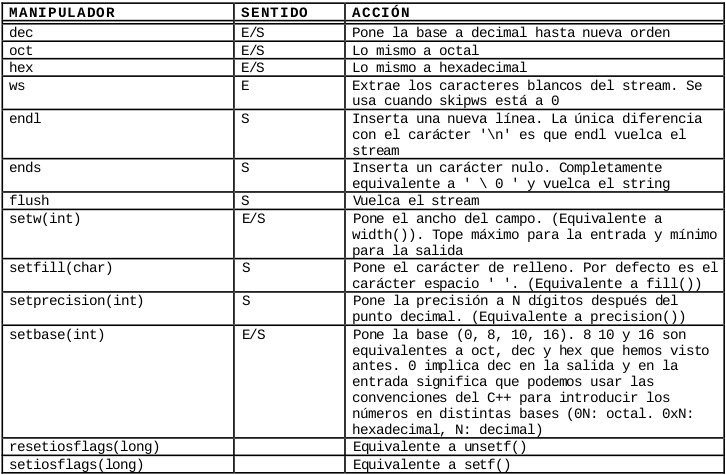
Manipuladores
Otras funciones de acceso a Streams
ostream& put(char);
Inserta un carácter en el stream de salida. Retorna el stream de salida.
int get();
Extrae el siguiente carácter del stream de entrada y lo retorna. Se retorna EOF si está vacío.
int peek();
Lo mismo que get() pero sin extraer el carácter.
istream& putback(char);
Pone de vuelta un carácter en el stream de entrada. En caso de querer meter otro carácter dará error. Retorna el stream de entrada.
istream& qet(char &):
Extrae el siguiente carácter del stream de entrada. Retorna el stream de entrada.
istream& get(char *s, int n, char t= '\n');
Extrae hasta n caracteres en s parando cuando se encuentra el carácter t o bien cuando se llega a fin de fichero o hasta que se han leído (n-1 ) caracteres . El carácter t no se almacena en s. pero sí un '\0' final en s. Retorna el stream de entrada. Falla sólo si no se extrae ningún carácter.
istream& getline(char *s, int n, char t= '\n');
Igual que la anterior pero en el caso de que se encuentre t se extrae y se añade en s.
istream& ignore(lnt n, int t= EOF);
Extrae y descarta hasta n caracteres o hasta que el carácter t se encuentre. El carácter t se saca del stream. Se retorna el stream de entrada.
int gcount();
Retorna el número de caracteres extraídos en la última extracción.
ostream& flush();
Vuelca el contenido del stream. Esto es vacía el buffer en la salida.
itream& read(char *s, int n);
Extrae n caracteres y los copia en s. Utilizar gcount() para ver cuantos caracteres han sido extraídos si la lectura termina en error.
ostream& seekp(streampos);
istream& seekg(streampos);
Posicionan el buffer de entrada o salida a la posición absoluta pasada como parámetro.
ostream& seekp(streamoff, seek_dir);
istream& seekg(streamoff, seek_dir);
Posiciona el buffer de entrada o salida relativamente en función del parámetro seek_dir:
enum seek_dir {
beg=0, // relativo al principio
cur=l, // relativo a la posición actual
end=2 // relativo al fin de fichero
}
streampos tellp();
Devuelve la posición actual del buffer de salida.
streampos tellg();
Posición actual del buffer de entrada.
ostream& write(const char* s, int n);
Inserta n caracteres en el stream de salida (caracteres nulos incluidos).
Ficheros
Apertura y cierre
fstream::fstream()
Constructor por defecto. Inicializa un objeto de stream sin abrir un fichero.
fstream::fstream(const char *f, int ap, int p= S_IREAD | S_IWRITE);
Constructor que crea un objeto fstream y abre un fichero f con el modo de apertura ap y el modo de protección p.
fstream::~fstream()
Destructor que vuelca el buffer del fichero y cierra el fichero (si no se ha cerrado ya).
fstream::open(const char *f, int ap, int p= S_IREAD | S_IWRITE);
Abre el fichero f con el modo de apertura ap y con el modo de protección p.
int fstream::is_open();
Retorna distinto de cero si el fichero está abierto.
fstream::close();
Cierra el fichero si no está ya cerrado.
Modos de apertura
in : Abierto para lectura
out : Abierto para escritura
ate : Colocarse al final del fichero
app : Modo append. Toda la escritura ocurre al final del fichero
trunc : Borra el contenido del fichero al abrir si ya existe. Es el valor por defecto si sólo se especifica out
nocreate : El fichero debe existir en el momento de la apertura, si no, falla
noreplace : El fichero no debe existir en el momento de la apertura, si no, falla
binary : Los caracteres '\r' y '\n' no son convertidos. Activar cuando se trabaje con ficheros de datos binarios. Cuando se trabaje con textos dejarlo por defecto que es desactivado
Modos de protección
Los modos de protección dependen del sistema operativo y por tanto no existe una definición estándar de los mismos. Sólo se definen:
S_IREAD : Permiso de lectura
S_IWRITE : Permiso de escritura
Otras funciones de gestión de ficheros
fstream (int fh)
Construye un stream usando un descriptor de fichero abierto existente descrito por fh.
attach(int fh);
Liga un stream con el descriptor fh. Si el stream ya está ligado da un error failbit.
fstream(int fh, char *p, int l);
Permite construir un stream con buffer que se liga a fh. p apunta a un buffer de l byte de longitud. Si p==NULL o l==O el stream no utilizará buffer.
setbuf(char *p, int l);
Permite cambiar el buffer y la longitud. Si p==NULL o l==O el stream pasará a no tener buffer.
istream& seekg(long offset, seek_dir mode= ios::beg);
ostream& seekp(long offset, seek_dir mode= ios::beg);
long tellg();
long tellp();
istream& read(signed char *s, int nbytes);
istream& read(unsigned char *s, int nbytes);
istream& read(void *p, int nbytes);
ostream& write(const signed char *s, int nbytes);
ostream& write(const unsigned char *s, int nbytes);
ostream& write(void p, int nbytes);
PROGRAMACIÓN EN C++
A continuación daremos unas nociones sobre lo que debe ser la programación en C++. Estas ideas no son las únicas aceptables, sólo pretendo que os sirvan como referencia inicial hasta que encontréis lo que más se acomode a vuestra forma de trabajar. Hay una frase que leí una vez que resume esto último: "Los estándares son buenos, cada uno debería tener el suyo".
El proceso de desarrollo
Dentro de la metodología de programación clásica se definen una serie de fases en el proceso de desarrollo de aplicaciones. No es mi intención repetirlas ahora, sólo quiero indicar que las nuevas metodologías de programación orientadas a objetos han modificado la forma de trabajar en estas etapas. El llamado ciclo de vida del software exigía una serie de etapas a la hora de corregir o modificar los programas, trabajando sobre todas las etapas del proceso de desarrollo. A mi modo de ver estas etapas siguen existiendo de una manera u otra, pero el trabajo sobre el análisis y diseño (que antes eran textos y diagramas, no código) es ahora posible realizarlo sobre la codificación: la idea de clase y objeto obliga a que los programas tengan una estructura muy similar a la descrita en las fases de análisis y diseño, por lo que un código bien documentado junto con herramientas que trabajan sobre el código (el browser, por ejemplo, nos muestra la estructura de las jerarquías de clases de nuestro programa) puede considerarse un modelo del análisis y el diseño (sobre todo del diseño, pero las clases nos dan idea del tipo de análisis realizado).
Mantenibilidad y documentación
Para mantener programas en C++ de forma adecuada debemos tener varias cosas en cuenta mientras programamos: es imprescindible un análisis y un diseño antes de implementar las clases, y todo este trabajo debe estar reflejado en la documentación del programa. Además, la estructura de clases nos permite una prueba de código mucho más fácil, podemos verificar clase a clase y método a método sin que ello afecte al resto del programa.
Debemos documentar el código abundantemente, es decir, debemos comentar todo lo que podamos los programas, explicando el sentido de las variables y objetos o la forma de implementar determinados algoritmos.
80Diseño e implementación
Debemos diseñar las aplicaciones en una serie de niveles diferentes: diseño de gestión de la información, diseño de la interface de la aplicación, etc.
A la hora de hacer programas es importante separar la parte de interface con el usuario de la parte realmente computacional de nuestra aplicación. Todo lo que hagamos a nivel de gestión de ficheros y datos debe ser lo más independiente posible de la interface de usuario en la que trabajamos. El hacer así las cosas nos permite realizar clases reutilizables y transportables a distintos entornos. Una vez tenemos bien definidas las clases de forma independiente de la interface con el usuario podemos definir esta e integrar una cosa y otra de la forma más simple y elegante posible.
Esta separación nos permitirá diseñar programas para SO con interface textual y transportarla a SO con ventanas y menús sin cambios en la funcionalidad de la aplicación.
Elección de clases
Un buen diseño en C++ (o en cualquier lenguaje orientado a objetos), pasa por un buen análisis de las clases que deben crearse para resolver nuestro programa. Una idea para identificar que deben ser clases, que deben ser objetos, que deben ser atributos o métodos de una clase y como deben relacionarse unas clases con otras es estudiar una descripción textual del problema a resolver. Por norma general los conceptos abstractos representarán clases, las características de estos conceptos (nombres) serán atributos, y las acciones (verbos) serán métodos. Las características que se refieran a más de un concepto nos definirán de alguna manera las relaciones de parentesco entre las clases y los conceptos relativos a casos concretos definirán los objetos de necesitamos.
Todo esto es muy vago, existen metodologías que pretenden ser sistemáticas a la hora de elegir clases y definir sus miembros, pero yo no acabo de ver claro como se pueden aplicar a casos concretos. Quizás la elección de clases y jerarquías tenga un poco de intuitivo. De cualquier forma, es fácil ver como definir las clases una vez tenemos un primer modelo de las clases para tratar un problema e intentamos bosquejar que tipo de flujo de control necesitamos para resolverlo.
Interfaces e implementación
Cuando definamos las clases de nuestra aplicación debemos intentar separar muy bien lo que es la interface externa de nuestra clase (la declaración de su parte protegida y pública) de la implementación de la clase (declaración de miembros privados y definición de métodos). Incluyo en la parte de implementación los miembros privados porque estos sólo son importantes para los métodos y funciones amigas de la clase, no para los usuarios de la clase. La correcta separación entre una cosa y otra permite que nuestra clase sea fácil de usar, de modificar y de transportar.
LIBRERÍAS DE CLASES
Como hemos visto, el C++ nos permite crear clases y jerarquías de clases reutilizables, es decir, las clases que definimos para programas concretos pueden utilizarse en otros programas si la definición es lo suficientemente general. Lo cierto es que existen una serie de clases que se pueden reutilizar siempre: las clases que definen aspectos de la interface con el SO (ventanas, menús, gestión de eventos, etc.) y las clases contenedor (pilas, colas, árboles, etc.). Existe otra serie de clases que pueden reutilizarse en aplicaciones concretas (clases para definir figuras geométricas en 2 y 3 dimensiones para aplicaciones de dibujo, clases para gestionar documentos de texto con formato en editores de texto, etc.).
En este bloque comentaremos algunas cosas a tener en cuenta a la hora de diseñar y trabajar con bibliotecas de clases.
Diseño de librerías
Lo primero que debemos plantearnos a la hora de diseñar una biblioteca de clases es si es necesario hacerlo. Por ejemplo, si queremos diseñar una biblioteca de clases de uso general para la gestión del SO, lo más normal es que estemos perdiendo el tiempo, ya que deben existir varias bibliotecas comerciales que hagan lo mismo con la ventaja de que deben estar probadas y lo único que nosotros debemos hacer es aprender a manejarlas.
Si nos decidimos a utilizar una biblioteca comercial lo más importante es saber cual es el soporte que esta biblioteca tiene, es decir, saber si la biblioteca tiene un futuro y si ese futuro pasa por la compatibilidad. Es habitual que las compañías que comercializan una biblioteca de clases vayan actualizando y mejorando sus clases, sacando al mercado sucesivas versiones de la misma. Lo más importante en estos casos es que las nuevas versiones añadan cosas o mejoren implementaciones, pero no modifiquen las interfaces de las clases antiguas, ya que esto puede hacer que nuestros viejos programas tengan que reescribirse para cada versión de una biblioteca. De todas formas, tenemos pocas garantías de que una compañía mantenga la compatibilidad en una biblioteca de software, aunque conforme vaya pasando el tiempo el mercado generará unos estándares que todo el mundo empleará.
Si la biblioteca que queremos escribir no existe (o las disponibles son malas), en primer lugar deberemos saber cuál es el alcance y potencia que queremos que tenga. Si lo que nos interesa es una biblioteca para uso personal podremos definirla a nuestro aire, pero es difícil que le sirva de mucho a otras personas.
Si por el contrario queremos que tenga un uso relativamente amplio (que la usen varias personas o grupos de personas) tendremos que comenzar pensando que el diseño debe documentarse y razonarse, definiendo las jerarquías y clases de la forma más simple y flexible posible. Es decir, tenemos que identificar que posibles clases se pueden definir en el ámbito que trata la biblioteca y definir las relaciones entre ellas. Debemos intentar que la biblioteca tenga el número mínimo de clases posibles de manera que sus declaraciones (su estructura externa, es decir, su interface con el usuario) sean fáciles de comprender y de ampliar (mediante herencia).
También es muy importante intentar que hagan el menor uso posible de las facilidades no estándar del C++, es decir, que no intenten aprovechar una arquitectura o un sistema operativo concretos. El aprovechamiento de estos recursos siempre se puede incorporar después en la implementación, pero el diseño pretende ser lo más general posible para que las implementaciones se puedan transportar de unas máquinas a otras. Sería una buena idea implementar una biblioteca sin optimizaciones (algoritmos sencillos, independencia de la máquina, poca gestión de memoria, etc.) y guardarla como primera versión. A partir de esta biblioteca iremos refinando (y documentando los refinamientos) para llegar a una versión definitiva probada y eficiente. Si hemos documentado todos los pasos de nuestro diseño e implementación el manejo de nuestra biblioteca será rápido de aprender y las modificaciones sencillas.
Otra cosa importante es considerar los errores que se pueden producir al usar las clases, para dotarlas de una gestión de errores adecuada.
Se que todas estas indicaciones son fáciles de dar pero difíciles de llevar a la práctica, lo fundamental es saber para qué estamos programando, si es para luego emplear la biblioteca muy a menudo es preferible trabajarla bien al principio en el diseño (comprobando que es el adecuado para lo que nos proponemos) y la implementación (comprobando la corrección y robustez del código), al final nos ahorrará tiempo.
Clases Contenedor
Un tipo de clases muy empleado es el de las clases contenedor. En la actualidad, la mayoría de compiladores incorporan las templates y una biblioteca específica de clases contenedor genéricas. Lo importante al emplear estas clases es tener en cuenta que cosas debemos de incorporar a nuestras clases para que trabajen adecuadamente con ellas. Es muy habitual que sea necesario definir alguna relación de orden en nuestras clases (sobrecarga de operadores relacionales).
Si queremos diseñar clases contenedor deberemos tener en cuenta que clase de objetos han de contener, he intentar que dependan lo menos posible de ellos. Lo habitual es que sólo necesitemos relaciones de orden (para árboles ordenados, por ejemplo) y de igualdad (para comprobar si un objeto está dentro de un contenedor). En la actualidad lo más razonable es emplear plantillas para definir este tipo de clases (cuando estas no existían se trabajaba con contenedores de punteros a objetos). También es importante considerar que es lo que queremos almacenar: objetos, punteros a objetos o referencias a objetos.
También hay que considerar si estas clases deben pertenecer o no a una jerarquía (es decir, si las queremos definir como objetos relacionados con los demás o sólo como almacenes de datos).
Por último hay que saber que existen muchas posibilidades alternativas para la gestión e implementación de contenedores, con diferente niveles de eficiencia temporal y espacial. La idea es intentar llegar a un compromiso entre ambas cosas, pero también puede ser útil definir varias alternativas para una misma clase y emplear en cada caso la que más convenga al programa por velocidad y espacio que necesita.
Clases para aplicaciones
En la actualidad existen bibliotecas comerciales que nos permiten escribir programas completos en entornos complejos como Windows, en pocas líneas. Esto se consigue gracias a la idea de clases de aplicación y de interacción con el SO. Si nosotros tenemos que escribir programas de gestión de bases de datos, por ejemplo, sabemos que lo habitual es que todos los programas tengan la misma estructura interna (implementación) y externa (interfaz con el usuario de la aplicación). Pues bien, hay bibliotecas que hacen uso de ese hecho y definen una jerarquía que permite controlar y definir estos objetos comunes, para implementar la aplicación bastará con usar objetos de las clases de la biblioteca y quizás definir unas pocas clases derivadas redefiniendo algunos métodos.
Yo creo que no falta mucho para que aparezca una o varias bibliotecas estándar para la construcción de determinados tipos de aplicaciones. Puede que así desaparezcan algunos lenguajes específicos bastante desafortunados (pero desgraciadamente muy extendidos).
Clases de Interface
Dentro de las clases para aplicación lo que si han aparecido son bibliotecas para definir la interface de las aplicaciones, pero la mayoría de estas bibliotecas son dependientes del Sistema Operativo, por lo que no son realmente estándar. Lo ideal sería que se definiera una interface gráfica estándar orientada a objetos (como las que de alguna manera definen los lenguajes SmallTalk y Oberon, este último implementado con un pequeño sistema operativo propio).
Hasta que no existan estas bibliotecas estándar tendremos que seguir estudiando bibliotecas distintas para cada sistema operativo y cada compilador concreto.
No es mala idea crearse una pequeña biblioteca de interface para nuestras aplicaciones de entorno textual, ya que estas suelen ser muy transportables.
Eficiencia temporal y gestión de memoria
A la hora de diseñar o utilizar una biblioteca son fundamentales dos cosas, la eficiencia temporal de las operaciones con los objetos de las clases y la gestión de memoria que se haga. El C++ es un lenguaje que pretende ser muy eficaz en estos aspectos, por lo que las bibliotecas deberían aprovechar al máximo las posibilidades disponibles.
Estandarización
En la actualidad se está refinando y ampliando el estándar del C++. En el último borrador del comité (28 Abril de 1995) se incorporan una serie de mejoras del lenguaje como la definción de espacios de nombres (asignar un ámbito a los identificadores para evitar conflictos en las biliotecas) o de operadores de conversión (casts) mucho más refinados.
Además, la bibloteca de clases está muy ampliada (en realidad sólo hemos visto la biblioteca de E/S, pero es que no había nada más estandarizado). El borrador divide la biblioteca en diez componentes:
1. Soporte al lenguaje: declara y define tipos y funciones que son usadas implicitamente por los programas escritos en C++.
2. Diagnósticos:define componentes que puden ser usados para detectar e informar de errores.
3. Utilidades generales: componentes usados por otros componentes de la biblioteca y que también se pueden usar en nuestros programas.
4. Cadenas(strings): Componentes para manipular secuencias de caracteres (los caracteres pueden ser tipos definidos por el usuario o char y w_char, que es un nuevo tipo de la biblioteca).
5. Localización: Componentes para soporte internacional, incluye facilidades para la gestión de formatos de fecha, unidades monetarias, orden de los caractéres, etc.
6. Contenedores: Componentes que se pueden emplear para manejar colecciones de información.
7. Iteradores: Componentes que los programas pueden emplear para recorrer contenedores, streams(E/S) y stream buffers (E/S).
8. Algoritmos:Componentes para realizar operaciones algorítmicas sobre contenedores y otras secuencias.
9. Numéricos:Componentes que se pueden emplear para realizar operaciones semi-numéricas. Define los complejos, operaciones con matrices y vectores, etc.
10. E/S:Componentes para realizar tareas de entrada/salida.
De momento parece que no se va a incorporar la E/S gráfica, pero es relativamente lógico, ya que el diseño de una biblioteca de ese tipo podría limitar mucho a la hora de aprovechar las capacidades de un SO concreto.
R ELACIÓN C/C++
No se puede usar en ANSI C
(1) Las clases y la programación orientada o objetos. Esta es la faceta más importante del C++; simularla en C es posible pero bastante complicada
(2) Los templates. En C se puede hacer algo parecido usando macros
(3) El tratamiento de errores: try , catch , throw . Intentar simular esto es muy complicado
(4) La sobrecarga y el "name-mangling". En C dos funciones con el mismo nombre deben tener el mismo tipo de parámetros. La única solución es usar macros o simplemente dar nombres diferentes a las funciones
(5) La sobrecarga de operadores
(6) Las funciones inline . En C se solían usar macros para hacer operaciones eficientes
(7) Los operadores new y delete . La gestión de memoria en C se hacía con funciones
(8) Los parámetros por defecto
(9) Los comentarios estilo C++: //
(10) Los casts estilo C++: cast ()
(11) El uso de asm
(12) El operador de campo: ::
(13) Las uniones y enumeraciones anónimas
(14) Las referencias y por ello, el pase de parámetros por referencia. Para pasar parámetros por referencia en C se usan punteros
(15) Flexibilidad de declaraciones. En C las variables se deben declarar y definir al principio del bloque actual. En C++ se pueden definir en cualquier parte
Diferencias entre C y C++
(1) Compatibilidad de tipos En ANSI C un puntero void es compatible con todos los punteros. En C++ es válido asignarle a un puntero no void un puntero void pero no lo contrario.
(2) Flexibilidad de constantes: Las constantes en C++ pueden ser usadas en cualquier lugar. En ANSI C en cambio lo siguiente seria incorrecto:
const int Len= 1000;
int Vector[Len];
(3) La longitud ( sizeof ) de un carácter en C es 2 o 4 como un entero (dependiendo del tamaño de palabra). En C++ es siempre 1.
(4) En C se necesita poner la palabra struct o union delante de cualquier estructura o unión que se haya definido:
struct point {
int x, y;
};
struct point p; // Obligatoria en C, opcional en C++
(6) En C++ una declaración de variable sin extern es considera siempre la definición de una variable. En cambio en ANSI C es considerado una tentativa y se pueden definir varias veces una variable en un fichero y será convertida a una sola definición
(7) En C++ el enlazado por defecto de una constante es static . En ANSI C es extern
(8) C y C++ interpretan la lista vacía de argumentos de forma diferente. En C la lista vacía suspende el chequeo de tipos. Así f() en C puede tomar cero o más argumentos de cualquier tipo. En C++ la lista vacía significa que no tiene parámetros. En C se utilizaría el parámetro void ( f(void) )
(9) En C está permitido el uso de una función no declarada, que se toma como una función si chequeo de tipos. En C++ toda función tiene que estar declarada
(10) En C++ no se puede hacer un return sin valor para una función que devuelva algo.
(11) C++ y ANSI C interpretan de forma diferente el tipo de cadena constante usada para inicializar un vector de caracteres. En C++ lo siguiente es ilegal mientras que en C está permitido:
char vocales[5] ="aeiou";