Tutorial Programación C++
Introducción a la Programación.
INTRODUCCIÓN
Para comenzar a estudiar cualquier lenguaje de programación se debe conocer cuales son los conceptos que soporta, es decir, el tipo de programación que vamos a poder realizar con él. Como el C++ incorpora características nuevas respecto a lenguajes como Pascal o C, en primer lugar daremos una descripción a los conceptos a los que este lenguaje da soporte, repasando los paradigmas de programación y centrándonos en la evolución desde la programación Funcional a la programación Orientada a Objetos. Más adelante estudiaremos el lenguaje de la misma manera, primero veremos sus características funcionales (realmente la parte que el lenguaje hereda de C) y después estudiaremos las extensiones que dan soporte a la programación orientada a objetos (el ++ de C++).
PARADIGMAS DE PROGRAMACIÓN
Según los conceptos en que se basa un lenguaje de programación tenemos distintas maneras de aproximarnos a la resolución de los problemas y diferentes estilos de programación. Podemos clasificar los lenguajes de programación en varios tipos:
— Imperativos
— Orientados a Objetos
— Funcionales
— Lógicos
Las dos primeras opciones se basan en la abstracción de los tipos de datos. Básicamente se trata de representar las características variables de los objetos mediante tipos que el ordenador pueda tratar, como por ejemplo números enteros o caracteres alfanuméricos. Nuestro programa será una colección de algoritmos que opere sobre los datos que hemos modelado. La diferencia entre las dos aproximaciones se verá en puntos posteriores.
Los lenguajes funcionales, al contrario que los imperativos, eliminan totalmente la idea de tipo de datos, se limitan a tratar todos los datos como símbolos y hacen hincapié en las operaciones que podemos aplicar sobre estos símbolos, agrupados en listas o árboles. Es importante indicar que en estos lenguajes se emplea únicamente el concepto de función aplicado a símbolos, siendo una de sus características principales el empleo de las funciones recursivas. Como ejemplo de este tipo de lenguajes podríamos citar el LISP.
1Los lenguajes lógicos son los que trabajan directamente con la lógica formal, se trata de representar relaciones entre conjuntos, para luego poder determinar si se verifican determinados predicados. El lenguaje lógico más extendido es el Prolog.
PROGRAMACIÓN IMPERATIVA
Como ya hemos mencionado anteriormente, la programación imperativa trata con tipos de datos y algoritmos, los primeros representan la información utilizada por los programas, mientras que los segundos se refieren a la manera en que tratamos esa información.
En los puntos que siguen revisaremos de forma breve los conceptos fundamentales de la programación imperativa clásica, también llamada programación procedural. La idea básica de esta aproximación es la de definir los algoritmos o procedimientos más eficaces para tratar los datos de nuestro problema.
Tipos de datos
Cuando nos planteamos la resolución de problemas mediante computador lo más usual es que queramos tratar con datos que son variables y cuantificables, es decir, que toman un conjunto de valores distintos entre un conjunto de valores posibles, además de poder almacenar los valores de estos datos en alguna forma aceptable para el computador (ya sea en la memoria o en periféricos de almacenamiento externo).
En un lenguaje de programación el concepto de tipo de datos se refiere al conjunto de valores que puede tomar una variable. Esta idea es similar a la que se emplea en matemáticas, donde clasificamos las variables en función de determinadas características, distinguiendo entre números enteros, reales o complejos. Sin embargo, en matemáticas, nosotros somos capaces de diferenciar el tipo de las variables en función del contexto, pero para los compiladores esto resulta mucho más difícil. Por este motivo debemos declarar explícitamente cada variable como perteneciente a un tipo. Este mecanismo es útil para que el computador almacene la variable de la forma más adecuada, además de permitir verificar que tipo de operaciones se pueden realizar con ella.
Se suelen diferenciar los tipos de datos en varias categorías:
— Tipos elementales, que son aquellos cuyos valores son atómicos y, por tanto, no pueden ser descompuestos en valores más simples. Entre las variables de estos tipos siempre encontramos definidas una serie de operaciones básicas: asignación de un valor, copia de valores entre variables y operaciones relacionales de igualdad o de orden (por lo tanto, un tipo debe ser un conjunto ordenado).
Los tipos más característicos son:
booleanos = {verdadero, falso}
enteros = {... -2, -1, 0, +1, +2, ...}
reales = {... -1.0, ..., 0.0, ..., +1.0, ...}
caracteres = {... 'a', 'b', ..., 'Z', ...}
Generalmente existen mecanismos para que el usuario defina nuevos tipos elementales por enumeración, es decir, definiendo el conjunto de valores explícitamente. Por ejemplo podríamos definir el tipo día como {lunes, martes, miércoles, jueves, viernes, sábado, domingo}, las variables definidas como día sólo podrían tomar estos valores.
Por último mencionaremos otro tipo de datos elemental de características especiales, el puntero, que es el tipo que almacena las direcciones de las variables (la dirección de memoria en la que se almacena su valor). Analizaremos este tipo más adelante.
— Tipos compuestos o estructurados, que son los tipos formados a partir de los elementales. Existen varias formas de agrupar los datos de tipos elementales:
La más simple es la estructura indexada, muy similar a los vectores o matrices de matemáticas, en donde lo que hacemos es relacionar unos índices (pertenecientes a un tipo de datos) con los valores de un tipo determinado. Sobre estas estructuras se pueden realizar las operaciones de consulta o asignación de un valor (a través de su índice).
Otra estructura compuesta muy importante es el registro, que no es más que una sucesión de elementos de distintos tipos, denominados campos, que llevan asociados un identificador. Sobre estos tipos se definen las operaciones de asignación y de acceso a un campo. Algunos lenguajes también soportan la operación de asignación para toda la estructura (la copia de todos los campos en un solo paso).
El tipo cadena de caracteres es un caso especial de tipo de datos, ya que algunos lenguajes lo incorporan como tipo elemental (con un tamaño fijo), mientras que en otros lenguajes se define como un vector de caracteres (de longitud fija o variable) que es una estructura indexada. Como se ve, los campos de un registro pueden ser de otros tipos compuestos, no sólo de tipos elementales.
— Tipos recursivos, que son un caso especial de tipos compuestos, introduciendo la posibilidad de definir un tipo en función de sí mismo.
Para terminar nuestro análisis de los tipos de datos, hablaremos de la forma en que los lenguajes de programación relacionan las variables con sus tipos y las equivalencias entre distintos tipos.
Hemos dicho que el empleo de tipos de datos nos sirve para que el computador almacene los datos de la forma más adecuada y para poder verificar las operaciones que hacemos con ellos. Sería absurdo que intentáramos multiplicar un carácter por un real pero, si el compilador no comprueba los tipos de los operandos de la multiplicación, esto sería posible e incluso nos devolvería un valor, ya que un carácter se representa en binario como un número entre 0 y 255. Para evitar que sucedan estas cosas los compiladores incorporan mecanismos de chequeo de tipos, verificando antes de cada operación que sus operandos son de los tipos esperados. El chequeo se puede hacer estática o dinámicamente. El chequeo estático se realiza en tiempo de compilación, es decir, antes de que el programa sea ejecutable. Para realizar este chequeo es necesario que las variables y los parámetros tengan tipos fijos, elegidos por el programador. El chequeo dinámico se realiza durante la ejecución del programa, lo que permite que las variables puedan ser de distintos tipos en tiempo de ejecución.
Por último señalaremos que existe la posibilidad de que queramos realizar una operación definida sobre un tipo de datos, por ejemplo reales, aplicada a una variable de otro tipo, por ejemplo entera. Para que podamos realizar esta operación debe de existir algún mecanismo para compatibilizar los tipos, convirtiendo un operando que no es del tipo esperado en éste, por ejemplo transformando un entero en real, añadiendo una parte decimal nula, o transformando un real en entero por redondeo.
Operadores y expresiones
Como ya hemos dicho con los datos de un tipo podemos realizar determinadas operaciones pero, ¿cómo las expresamos en un lenguaje de programación? Para resolver este problema aparecen lo que llamamos operadores. Podemos decir que un operador es un símbolo o conjunto de símbolos que representa la aplicación de una función sobre unos operandos. Cuando hablamos de los operandos no sólo nos referimos a variables, sino que hablamos de cualquier elemento susceptible de ser evaluado en alguna forma. Por ejemplo, si definimos una variable entera podremos aplicarle operadores aritméticos (+, -, *, /), de asignación (=) o relacionales (>, <, ...), si definimos una variable compuesta podremos aplicarle un operador de campo que determine a cual de sus componentes queremos acceder, si definimos un tipo de datos podemos aplicarle un operador que nos diga cual es el tamaño de su representación en memoria, etc.
Los operadores están directamente relacionados con los tipos de datos, puesto que se definen en función del tipo de operandos que aceptan y el tipo del valor que devuelven. En algunos casos es fácil olvidar esto, ya que llamamos igual a operadores que realizan operaciones distintas en función de los valores a los que se apliquen, por ejemplo, la división de enteros no es igual que la de reales, ya que la primera retorna un valor entero y se olvida del resto, mientras que la otra devuelve un real, que tiene decimales.
Un programa completo está compuesto por una serie de sentencias, que pueden ser de distintos tipos:
— declarativas, que son las que empleamos para definir los tipos de datos, declarar las variables o las funciones, etc., es decir, son aquellas que se emplean para definir de forma explícita los elementos que intervienen en nuestro programa,
— ejecutables, que son aquellas que se transforman en código ejecutable, y
— compuestas, que son aquellas formadas de la unión de sentencias de los tipos anteriores.
Llamaremos expresión a cualquier sentencia del programa que puede ser evaluada y devuelve un valor. Las expresiones más simples son los literales, que expresan un valor fijo explícitamente, como por ejemplo un número o una cadena de caracteres. Las expresiones compuestas son aquellas formadas por una secuencia de términos separados por operadores, donde los términos pueden ser literales, variables o llamadas a funciones (ya que devuelven un resultado).
Algoritmos y estructuras de control
Podemos definir un algoritmo de manera general como un conjunto de operaciones o reglas bien definidas que, aplicadas a un problema, lo resuelven en un número finito de pasos. Si nos referimos sólo a la informática podemos dar la siguiente definición:
Un procedimiento es una secuencia de instrucciones que pueden realizarse mecánicamente. Un procedimiento que siempre termina se llama algoritmo.
Al diseñar algoritmos que resuelvan problemas complejos debemos emplear algún método de diseño, la aproximación más sencilla es la del diseño descendente (top-down). El método consiste en ir descomponiendo un problema en otros más sencillos (subproblemas) hasta llegar a una secuencia de instrucciones que se pueda expresar en un lenguaje de alto nivel. Lo que haremos será definir una serie de acciones complejas y dividiremos cada una en otras más simples. Para controlar el orden en que se van desarrollando las acciones, utilizaremos las estructuras de control, que pueden ser de distintos tipos:
— condicionales o de selección, que nos permiten elegir entre varias posibilidades en función de una o varias condiciones,
— de repetición (bucles), que nos permiten repetir una serie de operaciones hasta que se verifique una condición o hayamos dado un número concreto de vueltas, y
— de salto, que nos permiten ir a una determinada línea de nuestro algoritmo directamente.
Funciones y procedimientos
En el punto anterior hemos definido los algoritmos como procedimientos que siempre terminan, y procedimiento como una secuencia de instrucciones que pueden realizarse mecánicamente, aquí consideraremos que un procedimiento es un algoritmo que recibe unos parámetros de entrada, y una función un procedimiento que, además de recibir unos parámetros, devuelve un valor de un tipo concreto. En lo que sigue emplearé los términos procedimiento y función indistintamente.
Lo más importante de estas abstracciones es saber como se pasan los parámetros, ya que según el mecanismo que se emplee se podrá o no modificar sus valores. Si los parámetros se pasan por valor, el procedimiento recibe una copia del valor que tiene la variable parámetro y por lo tanto no puede modificarla, sin embargo, si el parámetro se pasa por referencia, el procedimiento recibe una referencia a la variable que se le pasa como parámetro, no el valor que contiene, por lo que cualquier consulta o cambio que se haga al parámetro afectará directamente a la variable.
¿Por qué surgieron los procedimientos y las funciones? Sabemos que un programa según el paradigma clásico es una colección de algoritmos pero, si los escribiéramos todos seguidos, nuestro programa sería ilegible. Los procedimientos son un método para ordenar estos algoritmos de alguna manera, separando las tareas que realiza un programa. El hecho de escribir los algoritmos de manera independiente nos ayuda a aplicar el diseño descendente; podemos expresar cada subproblema como un procedimiento distinto, viendo en el programa cual ha sido el refinamiento realizado. Además algunos procedimientos se podrán reutilizar en problemas distintos.
Por último indicaremos que el concepto de procedimiento introduce un nivel de abstracción importante en la programación ya que, si queremos utilizar un procedimiento ya implementado para resolver un problema, sólo necesitamos saber cuáles son sus parámetros y cuál es el resultado que devuelve. De esta manera podemos mejorar o cambiar un procedimiento sin afectar a nuestro programa, siempre y cuando no cambie sus parámetros, haciendo mucho más fácil la verificación de los programas, ya que cuando sabemos que un procedimiento funciona correctamente no nos debemos volver a preocupar por él.
Constantes y variables
En los puntos anteriores hemos tratado las variables como algo que tiene un tipo y puede ser pasado como parámetro pero no hemos hablado de cómo o dónde se declaran, de cómo se almacenan en memoria o de si son accesibles desde cualquier punto de nuestro programa.
Podemos decir que un programa está compuesto por distintos bloques, uno de los cuales será el principal y que contendrá el procedimiento que será llamado al comenzar la ejecución del programa. Serán bloques el interior de las funciones, el interior de las estructuras de control, etc.
Diremos que el campo o ámbito de un identificador es el bloque en el que ha sido definido. Si el bloque contiene otros bloques también en estos el identificador será válido. Cuando hablo de identificador me refiero a su sentido más amplio: variables, constantes, funciones, tipos, etc. Fuera del ámbito de su definición ningún identificador tiene validez.
Clasificaremos las variables en función de su ámbito de definición en globales y locales. Dentro de un bloque una variable es local si ha sido definida en el interior del mismo, y es global si se ha definido fuera de el bloque pero podemos acceder a ella.
Como es lógico las variables ocupan memoria pero, como sólo son necesarias en el interior de los bloques donde se definen, durante la ejecución del programa serán creadas al entrar en su ámbito y eliminadas al salir de él. Así, habrá variables que existirán durante todo el programa (si son globales para todos los bloques) y otras que sólo existan en momentos muy concretos. Este mecanismo de creación y destrucción de variables permite que los programas aprovechen al máximo la memoria que les ha sido asignada.
Todo lo dicho anteriormente es válido para las variables declaradas estáticamente, pero existe otro tipo de variables cuya existencia es controlada por el programador, las denominadas variables dinámicas. Ya hablamos anteriormente de los punteros y dijimos entonces que eran las variables empleadas para apuntar a otras variables, pero ¿a qué nos referimos con apuntar? Sabemos que las variables se almacenan en memoria, luego habrá alguna dirección de memoria en la que encontremos su valor (que puede ocupar uno o varios bytes). Los punteros no son más que variables cuyo contenido es una dirección de memoria, que puede ser la de la posición del valor de otra variable.
Cuando deseamos crear variables de tipo dinámico el lenguaje de programación nos suele proporcionar alguna función estándar para reclamarle al S.O. espacio de memoria para almacenar datos, pero como no hemos definido variables que denoten a ese espacio, tendremos que trabajar con punteros. Es importante señalar que el espacio reservado de esta forma se considera ocupado durante todo el tiempo que se ejecuta el programa, a menos que el programador lo libere explícitamente, pero los punteros que contienen la dirección de ese espacio si son variables estáticas, luego dejan de existir al salir de un campo. Si salimos de un campo y no hemos liberado la memoria dinámica, no podremos acceder a ella (a menos que alguno de los punteros fuera global al ámbito abandonado), pero estaremos ocupando un espacio que no será utilizable hasta que termine nuestro programa.
Para terminar sólo diré que existen variables constantes (que ocupan memoria). Son aquellas que tienen un tipo y un identificador asociado, lo que puede ser útil para que se hagan chequeos de tipos o para que tengan una dirección de memoria por si algún procedimiento requiere un puntero a la constante.
PROGRAMACIÓN MODULAR
Con la programación procedural se consigue dar una estructura a los programas, pero no diferenciamos realmente entre los distintos aspectos del problema, ya que todos los algoritmos están en un mismo bloque, haciendo que algunas variables y procedimientos sean accesibles desde cualquier punto de nuestro programa.
Para introducir una organización en el tratamiento de los datos apareció el concepto de módulo, que es un conjunto de procedimientos y datos interrelacionados. Aparece el denominado principio de ocultación de información, los datos contenidos en un módulo no podrán ser tratados directamente, ya que no serán accesibles desde el exterior del mismo, sólo permitiremos que otro módulo se comunique con el nuestro a través de una serie de procedimientos públicos definidos por nosotros. Esto proporciona ventajas como poder modificar la forma de almacenar algunos de los datos sin que el resto del programa sea alterado o poder compilar distintos módulos de manera independiente. Además, un módulo bien definido podrá ser reutilizado y su depuración será más sencilla al tratarlo de manera independiente.
TIPOS ABSTRACTOS DE DATOS
Con los mecanismos de definición de tipos estructurados podíamos crear tipos de datos más complejos que los primitivos, pero no podíamos realizar más que unas cuantas operaciones simples sobre ellos. Sin embargo, los procedimientos nos permiten generalizar el concepto de operador. En lugar de limitarnos a las operaciones incorporadas a un lenguaje, podemos definir nuestros propios operadores y aplicarlos a operandos que no son de un tipo fundamental (por ejemplo, podemos implementar una rutina que multiplique matrices y utilizarla como si fuera un operador sobre variables del tipo matriz). Además, la estructura modular vista en el apartado anterior nos permite reunir en un solo bloque las estructuras que componen nuestro tipo y los procedimientos que operan sobre él. Surgen los denominados Tipos Abstractos de Datos (TAD).
Un TAD es una encapsulación de un tipo abstracto de datos, que contiene la definición del tipo y todas las operaciones que se pueden realizar con él (en teoría, algún operando o el resultado de las operaciones debe pertenecer al tipo que estamos definiendo). Esto permite tener localizada toda la información relativa a un tipo de datos, con lo que las modificaciones son mucho más sencillas, ya que desde el resto del programa tratamos nuestro TAD como un tipo elemental, accediendo a él sólo a través de los operadores que hemos definido.
El problema de esta idea está en que los lenguajes que soportan módulos pero no están preparados para trabajar con TAD sólo permiten que definamos los procedimientos de forma independiente, es decir, sin asociarlos al TAD más que por la pertenencia al módulo. Las variables del tipo únicamente se podrán declarar como estructuras, por lo que los procedimientos necesitarán que las incluyamos como parámetro. La solución adoptada por los nuevos lenguajes es incorporar mecanismos de definición de tipos de usuario que se comportan casi igual que los tipos del lenguaje.
PROGRAMACIÓN ORIENTADA A OBJETOS
La diferencia fundamental entre la programación pocedural y la orientada a objetos está en la forma de tratar los datos y las acciones. En la primera aproximación ambos conceptos son cosas distintas, se definen unas estructuras de datos y luego se define una serie de rutinas que operan sobre ellas. Para cada estructura de datos se necesita un nuevo conjunto de rutinas. En la programación orientada a objetos los datos y las acciones están muy relacionadas. Cuando definimos los datos (objetos) también definimos sus acciones. En lugar de un conjunto de rutinas que operan sobre unos datos tenemos objetos que interactuan entre sí.
Objetos y mensajes
Un Objeto es una entidad que contiene información y un conjunto de acciones que operan sobre los datos. Para que un objeto realice una de sus acciones se le manda un mensaje. Por tanto, la primera ventaja de la programación orientada a objetos es la encapsulación de datos y operaciones, es decir, la posibilidad de definir Tipos Abstractos de Datos.
De cualquier forma la encapsulación es una ventaja mínima de la programación orientada a objetos. Una característica mucho más importante es la posibilidad de que los objetos puedan heredar características de otros objetos. Este concepto se incorpora gracias a la idea de clase.
Clases
Cada objeto pertenece a una clase, que define la implementación de un tipo concreto de objetos. Una clase describe la información de un objeto y los mensajes a los que responde. La declaración de una clase es muy parecida a la definición de un registro, pero aquí los campos se llaman instancias de variables o datos miembro (aunque utilizaré el término atributo, que no suena tan mal en castellano). Cuando le mandamos un mensaje a un objeto, este invoca una rutina que implementa las acciones relacionadas con el mensaje. Estas rutinas se denominan métodos o funciones miembro. La definición de la clase también incluye las implementaciones de los métodos.
Se puede pensar en las clases como plantillas para crear objetos. Se dice que un objeto es una instancia de una clase. También se puede decir que un objeto es miembro de una clase.
Herencia y polimorfismo
Podemos definir clases en base a otra clase ya existente. La nueva clase se dice que es una subclase o clase derivada, mientras que la que ya existía se denomina superclase o clase base. Una clase que no tiene superclase se denomina clase raíz.
Una subclase hereda todos los métodos y atributos de su superclase, además de poder definir miembros adicionales (ya sean datos o funciones). Las subclases también pueden redefinir (override) métodos definidos por su superclase. Redefinir se refiere a que las subclase responde al mismo mensaje que su superclase, pero utiliza su propio método para hacerlo.
Gracias al mecanismo de redefinición podremos mandar el mismo mensaje a objetos de diferentes clases, esta capacidad se denomina polimorfismo.
Programación con objetos
A la hora de programar con objetos nos enfrentamos a una serie de problemas: ¿Qué clases debo crear?, ¿Cuándo debo crear una subclase? ¿Qué debe ser un método o un atributo? Lo usual es crear una jerarquía de clases, definiendo una clase raíz que da a todos los objetos un comportamiento común. La clase raíz será una clase abstracta, ya que no crearemos instancias de la misma. En general se debe definir una clase (o subclase de la clase raíz) para cada concepto tratado en la aplicación. Cuando necesitemos añadir atributos o métodos a una clase definimos una subclase. Los atributos deben ser siempre privados, y deberemos proporcionar métodos para acceder a ellos desde el exterior. Todo lo que se pueda hacer con un objeto debe ser un método.
El lenguaje C++
INTRODUCCIÓN
En este bloque introduciremos el lenguaje de programación C++. Comenzaremos por dar una visión general del lenguaje y después trataremos de forma práctica todos los conceptos estudiados en el bloque anterior, viendo como se implementan en el C++.
Trataremos de que el tema sea fundamentalmente práctico, por lo que estos apuntes se deben considerar como una pequeña introducción al lenguaje, no como una referencia completa. Los alumnos interesados en conocer los detalles del lenguaje pueden consultar la bibliografía.
CONCEPTOS BÁSICOS
Comenzaremos estudiando el soporte del C++ a la programación imperativa, es decir, la forma de definir y utilizar los tipos de datos, las variables, las operaciones aritméticas, las estructuras de control y las funciones. Es interesante remarcar que toda esta parte está heredada del C, por lo que también sirve de introducción a este lenguaje.
Estructura de los programas
El mínimo programa de C++ es:
main() { }
Un programa será una secuencia de líneas que contendrán sentencias, directivas de compilación y comentarios.
Las sentencias simples se separan por punto y coma y las compuestas se agrupan en bloques mediante llaves.
Las directivas serán instrucciones que le daremos al compilador para indicarle que realice alguna operación antes de compilar nuestro programa, las directivas comienzan con el símbolo # y no llevan punto y coma. Los comentarios se introducirán en el programa separados por /* y */ o comenzándolos con // . Los comentarios entre /* y */ pueden tener la longitud que queramos, pero no se anidan, es decir, si escribimos /* hola /* amigo */ mío */ , el compilador interpretará que el comentario termina antes de mío, y dará un error. Los comentarios que comienzan por // sólo son válidos hasta el final de la línea en la que aparecen. Un programa simple que muestra todo lo que hemos visto puede ser el siguiente:
/*
Este es un programa mínimo en C++, lo único que hace es escribir una frase
en la pantalla
*/
#include
int main()
{
cout << "Hola guapo\n";
// imprime en la pantalla la frase "hola guapo"
}
La línea que empieza por # es una directiva. En este caso indica que se incluya el fichero "iostream.h", que contiene las definiciones para entrada/salida de datos en C++.
En la declaración de main() hemos incluido la palabra int , que indica que la función devuelve un entero. Este valor se le entrega al sistema operativo al terminar el programa. Si no se devuelve ningún valor el sistema recibe un valor aleatorio.
La sentencia separada ente llaves indica que se escriba la frase "Hola guapo". El operador << ("poner en") escribe el segundo argumento en el primero. En este caso la cadena "Hola guapo\n" se escribe en la salida estándar ( cout ). El carácter \ seguido de otro carácter indica un solo carácter especial, en este caso el salto de línea ( \n ).
Veremos el tema de la entrada salida estándar más adelante. Hay que indicar que las operaciones de E/S se gestionan de forma diferente en C y C++, mientras que el C proporciona una serie de funciones (declaradas en el fichero "stdio.h"), el C++ utiliza el concepto de stream, que se refiere al flujo de la información (tenemos un flujo de entrada que proviene de cin y uno de salida que se dirige a cout) que se maneja mediante operadores de E/S.
Por último señalar que debemos seguir ciertas reglas al nombrar tipos de datos, variables, funciones, etc. Los identificadores válidos del C++ son los formados a partir de los caracteres del alfabeto (el inglés, no podemos usar ni la ñ ni palabras acentuadas), los dígitos (0..9) y el subrayado ( _ ), la única restricción es que no podemos comenzar un identificador con un dígito (es así porque se podrían confundir con literales numéricos). Hay que señalar que el C++ distingue entre mayúsculas y minúsculas, por lo que Hola y hola representan dos cosas diferentes. Hay que evitar el uso de identificadores que sólo difieran en letras mayúsculas y minúsculas, porque inducen a error.
Tipos de datos y operadores
Los tipos elementales definidos en C++ son:
char , short , int , long , que representan enteros de distintos tamaños (los caracteres son enteros de 8 bits)
float , double y long double , que representan números reales (en coma flotante).
Para declarar variables de un tipo determinado escribimos el nombre del tipo seguido del de la variable. Por ejemplo:
int i;
double d;
char c;
Sobre los tipos elementales se pueden emplear los siguientes operadores aritméticos:
+ (más, como signo o como operación suma)
- (menos, como signo o como operación resta)
* (multiplicación)
/ (división)
% (resto)
Y los siguientes operadores relacionales:
== (igual)
!= (distinto)
< (menor que)
> (mayor que)
<= (menor o igual que)
>= (mayor o igual que)
El operador de asignación se representa por = .
En la bibliografía del C++ se suelen considerar como tipos derivados los construidos mediante la aplicación de un operador a un tipo elemental o compuesto en su declaración. Estos operadores son:
* Puntero
& Referencia
[] Vector (Array)
() Función
Los tipos compuestos son las estructuras (struct), las uniones (unión) y las clases (class).
Estructuras de control
Como estructuras de control el C++ incluye las siguientes construcciones:
condicionales:
if instrucción de selección simple
switch instrucción de selección múltiple
bucles:
do-while instrucción de iteración con condición final
while instrucción de iteración con condición inicial
for instrucción de iteración especial (similar a las de repetición con contador)
de salto:
break instrucción de ruptura de secuencia (sale del bloque de un bucle o instrucción condicional)
continue instrucción de salto a la siguiente iteración (se emplea en bucles para saltar a la posición donde se comprueban las condiciones)
goto instrucción de salto incondicional (salta a una etiqueta)
return instrucción de retorno de un valor (se emplea en las funciones)
Veremos como se manejan todas ellas en el punto dedicado a las estructuras de control.
Funciones
Una función es una parte con nombre de un programa que puede ser invocada o llamada desde cualquier otra parte del programa cuando haga falta. La sintaxis de las funciones depende de si las declaramos o las definimos.
La declaración se escribe poniendo el tipo que retorna la función seguido de su nombre y de una lista de parámetros entre paréntesis (los parámetros deben ser de la forma tipo-param [nom_param] , donde los corchetes indican que el nombre es opcional), para terminar la declaración ponemos punto y coma (recordar que una declaración es una sentencia). Para definir una función se escribe el tipo que retorna, el nombre de la función y una lista de parámetros entre paréntesis (igual que antes, pero aquí si que es necesario que los parámetros tengan nombre). A continuación se abre una llave, se escriben las sentencias que se ejecutan en la función y se cierra la llave.
Un ejemplo de declaración de función sería:
int eleva_a_n (int, int);
int eleva_a_n (int x, int n)
{
if (n<0) error ("exponente negativo");
switch (n) {
case 0: return 1;
case 1: return x;
default: return eleva_a_n (x, n-1);
}
}
Soporte a la programación modular
El soporte a la programación modular en C++ se consigue mediante el empleo de algunas palabras clave y de las directivas de compilación.
Lo más habitual es definir cada módulo mediante una cabecera (un archivo con la terminación .h ) y un cuerpo del modulo (un archivo con la terminación .c , .cpp , o algo similar, depende del compilador). En el archivo cabecera (header) ponemos las declaraciones de funciones, tipos y variables que queremos que sean accesibles desde el exterior y en el cuerpo o código definimos las funciones publicas o visibles desde el exterior, además de declarar y definir variables, tipos o funciones internas a nuestro módulo.
Si queremos utilizar en un módulo las declaraciones de una cabecera incluimos el archivo cabecera mediante la directiva #include . También en el fichero que empleamos para definir las funciones de una cabecera se debe incluir el .h que define.
Existe además la posibilidad de definir una variable o función externa a un módulo mediante el empleo de la palabra extern delante de su declaración.
Por último indicar que cuando incluimos una cabecera estándar (como por ejemplo "iostream.h") el nombre del fichero se escribe entre menor y mayor ( #include
Soporte a los Tipos de Datos Abstractos
Para soportar los tipos de datos se proporcionan mecanismos para definir operadores y funciones sobre un tipo definido por nosotros y para restringir el acceso a las operaciones a los objetos de este tipo. Además se proporcionan mecanismos para redefinir operadores e incluso se soporta el concepto de tipos genéricos mediante las templates (plantillas).
También se define un mecanismo para manejo de excepciones que permite que controlemos de forma explícita los errores de nuestro programa.
Soporte a la programación Orientada a Objetos
Para soportar el concepto de programación orientada a objetos se incluyen diversos mecanismos:
— declaración de clases (usando la palabra class)
— de paso de mensajes a los objetos (realmente son llamadas a funciones)
— protección de los métodos y atributos de las clases (definición de métodos privados, protegidos y públicos)
— soporte a la herencia y polimorfismo (incluso se permite la herencia múltiple, es decir, la definición de una clase que herede características de dos clases distintas)
Es interesante señalar que el soporte a objetos complementa a los mecanismos de programación modular, encapsulando aun más los programas.
TIPOS DE DATOS, OPERADORES Y EXPRESIONES
Tipos de datos
Para declarar una variable ponemos el nombre del tipo seguido del de la variable. Podemos declarar varias variables de un mismo tipo poniendo el nombre del tipo y las variables a declarar separadas por comas:
int i, j,k;
Además podemos inicializar una variable a un valor en el momento de su declaración:
int i=100;
Cada tipo definido en el lenguaje (o definido por el usuario) tiene un nombre sobre el que se pueden emplear dos operadores:
sizeof - que nos indica la memoria necesaria para almacenar un objeto del tipo, y
new - que reserva espacio para almacenar un valor del tipo en memoria.
Tipos elementales
El C++ tiene un conjunto de tipos elementales correspondientes a las unidades de almacenamiento típicas de un computador y a las distintas maneras de utilizarlos:
— enteros:
char
short int
int
long int
— reales (números en coma flotante):
float
double
long double
La diferencia entre los distintos tipos enteros (o entre los tipos reales) está en la memoria que ocupan las variables de ese tipo y en los rangos que pueden representar. A mayor tamaño, mayor cantidad de valores podemos representar. Con el operador sizeof podemos saber cuanto ocupa cada tipo en memoria.
Para especificar si los valores a los que se refieren tienen o no signo empleamos las palabras signed y unsigned delante del nombre del tipo (por ejemplo unsigned int para enteros sin signo).
Para tener una notación más compacta la palabra int se puede eliminar de un nombre de tipo de más de una palabra, por ejemplo short int se puede escribir como short, unsigned es equivalente a unsigned int , etc.
El tipo entero char es el que se utiliza normalmente para almacenar y manipular caracteres en la mayoría de los computadores, generalmente ocupa 8 bits (1byte), y es el tipo que se utiliza como base para medir el tamaño de los demás tipos del C++.
Un tipo especial del C++ es el denominado void (vacío). Este tipo tiene características muy peculiares, ya que es sintácticamente igual a los tipos elementales pero sólo se emplea junto a los derivados, es decir, no hay objetos del tipo void Se emplea para especificar que una función no devuelve nada o como base para punteros a objetos de tipo desconocido (esto lo veremos al estudiar los punteros). Por ejemplo:
void BorraPantalla (void);
indica que la función BorraPantalla no tiene parámetros y no retorna nada.
Tipos enumerados
Un tipo especial de tipos enteros son los tipos enumerados. Estos tipos sirven para definir un tipo que sólo puede tomar valores dentro de un conjunto limitado de valores. Estos valores tienen nombre, luego lo que hacemos es dar una lista de constantes asociadas a un tipo.
La sintaxis es:
enum booleano {FALSE, TRUE}; // definimos el tipo booleano
Aquí hemos definido el tipo booleano que puede tomar los valores FALSE o TRUE. En realidad hemos asociado la constante FALSE con el número 0, la constante TRUE con 1, y si hubiera más constantes seguiríamos con 2, 3, etc. Si por alguna razón nos interesa dar un número concreto a cada valor podemos hacerlo en la declaración:
enum colores {rojo = 4, azul, verde = 3, negro = 1};
azul tomará el valor 5 (4+1), ya que no hemos puesto nada. También se pueden usar números negativos o constantes ya definidas.
Para declarar un variable de un tipo enumerado hacemos:
enum booleano test; // sintaxis de ANSI C
booleano test; // sintaxis de C++
En ANSI C los enumerados son compatibles con los enteros, en C++ hay que convertir los enteros a enumerado:
booleano test = (booleano) 1; // asigna TRUE a test (valor 1)
Si al definir un tipo enumerado no le damos nombre al tipo declaramos una serie de constantes:
enum { CERO, UNO, DOS };
Hemos definido las constantes CERO, UNO y DOS con los valores 0, 1 y 2.
Tipos derivados
De los tipos fundamentales podemos derivar otros mediante el uso de los siguientes operadores de declaración:
* Puntero
& Referencia
[] Vector (Array)
() Función
Ejemplos:
int *n; // puntero a un entero
int v[20]; // vector de 20 enteros
int *c[20]; // vector de 20 punteros a entero
void f(int j); // función con un parámetro entero
El problema más grave con los tipos derivados es la forma de declararlos: los punteros y las referencias utilizan notación prefija y los vectores y funciones usan notación postfija. La idea es que las declaraciones se asemejan al uso de los operadores de derivación. Para los ejemplos anteriores haríamos lo siguiente:
int i; // declaración de un entero i
i = *n; // almacenamos en i el valor al que apunta n
i = v[2] // almacenamos en i el valor de el tercer elemento de v
// (recordad que los vectores empiezan en 0)
i = *v[2] // almacenamos en i el valor al que apunta el tercer puntero de v
f(i) // llamamos a la función f con el parámetro i
int *c[20]; // vector de 20 punteros a entero
int (*p)[20] // puntero a vector de 20 enteros
int x,y,z; // declaración de tres variables enteras
int *i, j; // declaramos un puntero a entero (i) y un entero (j)
int v[10], *p; // declaramos un vector de 10 enteros y un puntero a entero
A continuación veremos los tipos derivados con más detalle, exceptuando las funciones, a las que dedicaremos un punto completo del bloque más adelante.
Punteros
Para cualquier tipo T , el puntero a ese tipo es T* . Una variable de tipo T* contendrá la dirección de un valor de tipo T . Los punteros a vectores y funciones necesitan el uso de paréntesis:
int *pi // Puntero a entero
char **pc // Puntero a puntero a carácter
int (*pv)[10] // Puntero a vector de 10 enteros
int (*pf)(float) // Puntero a función que recibe un real y retorna un entero
char c1 = 'a'; // c1 contiene el carácter 'a'
char *p = & c1; // asignamos a p la dirección de c1 (& es el operador referencia)
char c2 = *p; // ahora c2 vale lo apuntado por p ('a')
Vectores
Para un tipo T, T[n] indica un tipo vector con n elementos. Los índices del vector empiezan en 0, luego llegan hasta n-1 . Podemos definir vectores multidimensionales como vectores de vectores:
int v1[10]; // vector de 10 enteros
int v2[20][10]; // vector de 20 vectores de 10 enteros (matriz de 20*10)
v1[3] = 15; // el elemento con índice 3 vale 15
v2[8][3] = v1[3]; // el elemento 3 del vector 8 de v2 vale lo mismo que v[3]
Ejemplos:
int v1[5] = {2, 3, 4, 7, 8};
char v2[2][3] = {{'a', 'b', 'c'}, {'A', 'B', 'C'} }; // vect. multidimensional
int v3[2] = {1, 2, 3, 4}; // error: sólo tenemos espacio para 2 enteros
char c1[5] = {'h','o','l','a','\0'}; // cadena "hola"
char c2[5] = "hola"; // lo mismo
char c3[] = "hola"; // el compilador le da tamaño 5 al vector
char vs[3][] = {"uno", "dos", "tres"} // vector de 3 cadenas (3 punteros a carácter)
Una referencia es un nombre alternativo a un objeto, se emplea para el paso de argumentos y el retorno de funciones por referencia. T& significa referencia a tipo T.
Las referencias tienen restricciones:
1. Se deben inicializar cuando se declaran (excepto cuando son parámetros por referencia o referencias externas).
2. Cuando se han inicializado no se pueden modificar.
3. No se pueden crear referencias a referencias ni punteros a referencias.
Ejemplos:
int a; // variable entera
int &r1 = a; // ref es sinónimo de a
int & r2; // error, no está inicializada
extern int & r3; // válido, la referencia es externa (estará inicializada en otro módulo)
int &&r4=r1; // error: referencia a referencia
Existen cuatro tipos compuestos en C++:
Estructuras
Uniones
Campos de bits
Clases
Estructuras
Las estructuras son el tipo equivalente a los registros de otros lenguajes, se definen poniendo la palabra struct delante del nombre del tipo y colocando entre llaves los tipos y nombres de sus campos. Si después de cerrar la llave ponemos una lista de variables las declaramos a la vez que definimos la estructura. Si no, luego podemos declarar variables poniendo struct nomtipo (ANSI C, C++) o nomtipo (C++).
Ejemplo:
struct persona {
int edad;
char nombre[50];
} empleado;
struct persona alumno; // declaramos la variable alumno de tipo persona (ANSI C)
persona profesor; // declaramos la variable profesor de tipo persona
persona *p; // declaramos un puntero a una variable persona
persona juan= {21, "Juan Pérez"};
Para acceder a los campos de una estructura ponemos el nombre de la variable, un punto y el nombre del campo. Si trabajamos con punteros podemos poner -> en lugar de dereferenciar el puntero y poner un punto (esto lo veremos en el punto de variables dinámicas):
alumno.edad = 20; // el campo edad de alumno vale 20
p->nombre = "Pepe"; // el nombre de la estructura apuntada por p vale "Pepe"
(*p).nombre = "Pepe"; // igual que antes
Uniones
Las uniones son idénticas a las estructuras en su declaración (poniendo union en lugar de struct ), con la particularidad de que todos sus campos comparten la misma memoria (el tamaño de la unión será el del campo con un tipo mayor).
Es responsabilidad del programador saber que está haciendo con las uniones, es decir, podemos emplear el campo que queramos, pero si usamos dos campos a la vez uno machacará al otro.
Ejemplo:
union codigo {
int i;
float f;
} cod;
cod.i = 10; // i vale 10
cod.f = 25e3f; // f vale 25 * 1000, i indefinida (ya no vale 10)
Ejemplo:
struct {
int i;
char n[20]
} reg; // Podemos usar la variable reg
union {
int i;
float f;
}; // i y f son variables, pero se almacenan en la misma memoria
Un campo de bits es una estructura en la que cada campo ocupa un numero determinado de bits, de forma que podemos tratar distintos bits como campos independientes, aunque estén juntos en una misma palabra de la máquina.
Ejemplo:
struct fichero{
:3 // nos saltamos 3 bits
unsigned int lectura : 1; // reservamos un bit para lectura
unsigned int escritura : 1;
unsigned int ejecución : 1;
:0 // pasamos a la siguiente palabra
unsigned int directorio: 8;
} flags;
flags.lectura = 1; // ponemos a 1 el bit de lectura
Clases
Las clases son estructuras con una serie de características especiales, las estudiaremos en profundidad en un punto del bloque.
Constantes (literales)
Hay cuatro tipos de literales en C++:
Literales enteros
Octales (en base ocho), si empiezan por cero, p. ej. 023 equivale a 10011 en binario o a 19 en decimal
Hexadecimales (en base dieciséis), si empiezan por 0x, p.ej. 0x2F que equivale a 101111 en binario o a 47 en decimal. En hexadecimal los valores del 10 al 15 se representan por A, B, C, D, E, y F (en mayúsculas o minúsculas).
Decimales, que son los que no empiezan por 0.
A cada uno de estos literales les podemos añadir un sufijo para indicar que son sin signo (sufijo u o U ) o para forzar a que sean de tipo long (sufijo l o L ), por ejemplo 23L es el entero 23 de tipo long , 0xFu es el entero 15 sin signo. También podemos mezclar los sufijos: 12Lu entero 12 sin signo de tipo long.
Literales reales
Una constante en coma flotante se escribe con la parte entera y la decimal separadas por punto, y opcionalmente se puede escribir la letra e o E y un exponente.
El tipo de constante depende del sufijo:
Sin sufijo: double
f, F : float
l, L : long double
Ejemplos:
1.8e3 // 1.8 * 103 == 1800 de tipo double
0.1L // valor 0.1 long double
-1e-3f// -0.001 float
4. // 4.0 double
.12 // 0.12 double
Los caracteres se delimitan entre dos apóstrofes '' . Dentro de los apóstrofes sólo podemos escribir un carácter, excepto cuando son caracteres especiales, que se codifican mediante el carácter de escape \ seguido de otro carácter .
Ejemplos:
'a' // carácter a
' ' // espacio en blanco (es un carácter)
'\\' // carácter \ (es un carácter especial)
'' // error: debe haber un carácter entre los apóstrofes
'ab' // error: pero sólo uno
Caracteres especiales más utilizados:
\n // salto de línea
\t // tabulador horizontal
\v // tabulador vertical
\b // retroceso
\r // retorno de carro
\f // salto de página
\a // alerta (campana)
\\ // carácter \
\? // interrogante
\' // comilla simple
\" // comilla doble
\ooo // carácter ASCII dado por tres dígitos octales (ooo serán dígitos)
\xhh // carácter ASCII dado por dos dígitos hexadecimales (hh serán dígitos)
\0 // carácter nulo
Una cadena es un a secuencia de caracteres escrita entre comillas dobles y terminada con el carácter nulo ( \0 ).
Ejemplos:
"hola" // equivale a 'h','o','l','a','\0'
"" // equivale a '\0'
"'" // equivale a '\'', '\0'
"\'" // equivale a '\'', '\0'
""" // error, para escribir " dentro de una cadena lo correcto sería "\""
"ho""la" // se concatenan, equivale a 'h','o','l','a','\0'
Alcance o ámbito de las variables
Las variables existen sólo dentro del bloque en el que se definen, es decir, se crean cuando se entra en el bloque al que pertenecen y se destruyen al salir de él.
19Para acceder a variables que se definen en otros módulos la declaramos en nuestro módulo precedida de la palabra extern.
Si queremos que una variable sea local a nuestro módulo la definimos static , de manera que es inaccesible desde el exterior de nuestro módulo y además permanece durante todo el tiempo que se ejecute el programa (no se crea al entrar en el módulo ni se destruye al salir, sino que permanece todo el tiempo) guardando su valor entre accesos al bloque.
Si queremos que una variable no pueda ser modificada la declaramos const , tenemos que inicializarla en su declaración y mantendrá su valor durante todo el programa. Estas variables se emplean para constantes que necesitan tener una dirección (para pasarlas por referencia).
El operador ::
Dentro de un bloque podemos emplear el operador :: para acceder a variables declaradas en un bloque superior. Este operador sólo es útil cuando en un bloque interno tenemos una variable con un nombre igual a otro externo (la variable accesible será la interna, pero con :: accederemos a la externa). Veremos que el operador :: se usa fundamentalmente para clases.
Ejemplo:
main () {
int v;
...
{
char v;
v = 5; // asigna 5 a la variable char (interna)
::v=9 + v; // asigna 9 + 5 (valor de v interna) a la variable int más externa
}
}
Si queremos que una variable sea comprobada cada vez que la utilicemos la declararemos precedida de la palabra volatile , esto es útil cuando definimos variables que almacenan valores que no sólo modifica nuestro programa (por ejemplo una variable que utiliza el Hardware o el SO).
Variables register
Podemos intentar hacer más eficientes nuestros programas indicándole al compilador que variables usamos más a menudo para que las coloque en los registros. Esto se hace declarando la variable precedida de la palabra register . No tenemos ninguna garantía de que el compilador nos haga caso, depende del entorno de desarrollo que empleemos.
Conversiones de tipos
Conversiones implícitas
Cuando trabajamos con tipos elementales podemos mezclarlos en operaciones sin realizar conversiones de tipos, ya que el compilador se encarga de aproximar al valor de mayor precisión. De cualquier forma debemos ser cuidadosos a la hora de mezclar tipos, ya que la conversión que realiza el compilador puede no ser la que esperamos.
Conversiones explícitas (casting)
Para indicar la conversión explícita de un tipo en otro usamos el nombre del tipo, por ejemplo si tenemos i de tipo int y j de tipo long , podemos hacer i=(long)j (sintaxis del C, válida en C++) o i=long(j) (sintaxis del C++). Hay que tener en cuenta que hay conversiones que no tienen sentido, como pasar un long a short si el valor que contiene no cabe, o convertir un puntero a entero, por ejemplo.
Más adelante veremos que para los tipos definidos por nosotros podemos crear conversores a otros tipos.
Operadores y expresiones
El C++ tiene gran cantidad de operadores de todo tipo, en este punto veremos de forma resumida todos ellos, para luego dar una tabla con su precedencia y su orden de asociatividad. Antes de pasar a listar los operadores por tipos daremos unas definiciones útiles para la descripción de la sintaxis de los operadores:
Operandos LValue (left value)
Son aquellos operandos que cumplen las siguientes características:
— Pueden ser fuente de una operación.
— Pueden ser destino de una operación.
— Se puede tomar su dirección.
En definitiva un LValue es cualquier operando que este almacenado en memoria y se pueda modificar.
Expresiones
Como ya dijimos en el bloque anterior, una expresión es cualquier sentencia del programa que puede ser evaluada y devuelve un valor.
Lista de operadores según su tipo
Operadores aritméticos:
+ Suma - Resta * Producto / División: entera para escalares, real para reales % Módulo: retorna el resto de una división entre enteros -(unario) Cambio de signo +(unario) No hace nada
Operadores de incremento y decremento:
++ incremento en uno del operando LValue al que se aplica.
-- decremento en uno del operando LValue al que se aplica.
Estos operadores pueden ser prefijos o postfijos. Si son prefijos el operando se incrementa (decrementa) antes de ser evaluado en una expresión, si son postfijos el operando se incrementa (decrementa) después de la evaluación. Operadores relacionales:
> Mayor
< Menor
>= Mayor o igual
<= Menor o Igual
== Igual
!= Distinto
Como el C++ no tiene definido el tipo booleano el resultado de una comparación es 0 si no tiene éxito (FALSE) o distinto de cero (TRUE, generalmente 1) si si que lo tiene.
Operadores lógicos:
&& AND lógico
|| OR lógico
! NOT lógico
Toman expresiones como operandos, retornando verdadero o falso como en los operadores relacionales
Operadores de bit:
& Producto binario de bits (AND).
| Suma binaria de bits (OR).
^ Suma binaria exclusiva de bits (XOR).
<< Desplazamiento hacia la izquierda del primer operando tantos bits como indique el segundo operando.
<< Desplazamiento hacia la derecha del primer operando tantos bits como indique el segundo operando.
~ (unario) Complemento a uno (cambia unos por ceros).
- (unario) Complemento a dos (cambio de signo).
Estos operadores tratan los operandos como palabras de tantos bits como tenga su tipo, su tipo sólo puede ser entero (char, short, int, long).
Operadores de asignación:
= Asignación de la expresión de la derecha al operando de la izquierda.
Si delante del operador de asignación colocamos cualquiera de los siguientes operadores asignaremos al lado izquierdo el resultado de aplicar el operador al lado izquierdo como primer operando y el lado derecho como segundo operando:
+ - * / % << >> & ^ |
Ejemplos:
int i = 25;
int v[20];
i /= 2; // equivale a poner i = i / 2
v[i+3] += i * 8; // equivale a v[i+3] = v[i+3] + (i * 8)
Sirve para evaluar distintas expresiones seguidas, pero sólo se queda con el resultado de la última.
Ejemplo:
int i = (1, 2, 3); // i toma el valor 3
int v = (Randomize (), Rand()); // El Randomize se ejecuta, pero v toma el valor retornado por Rand()
:: Visto en el punto de las variables, también se usa en las clases
Operadores de indirección:
* -- Indirección
& -- Dirección (referencia)
-> -- Puntero selector de miembro o campo
. -- Selector de miembro o campo
[] -- Subíndice
->* -- Puntero selector de puntero a miembro
.* -- Selector de puntero a miembro
Los usos de estos operadores que aún no hemos visto se estudiarán más adelante
Operador condicional:
?: Expresión condicional
Este operador es equivalente a una expresión condicional, lo que hacemos es evaluar el primer operando y si es cierto retornamos el segundo operando, en caso contrario retornamos el tercer operando.
Ejemplo:
max = (a>b) ? a : b; // si a es mayor que b max vale a, sino max vale b
sizeof - var Nos da el tamaño de una variable
sizeof (tipo) - Nos da el tamaño de un tipo de datos
Estos operadores nos devuelven el tamaño en bytes.
Precedencia, asociatividad y orden de evaluación
La precedencia de los operadores nos permite evitar el uso de paréntesis (que es lo que más precedencia tiene) en expresiones sencillas. Veremos la precedencia de los operadores en función del orden de la tabla, los primeros bloques serán los de mayor precedencia.
También indicaremos en la tabla el orden en que se asocian los operandos (si se pueden asociar).
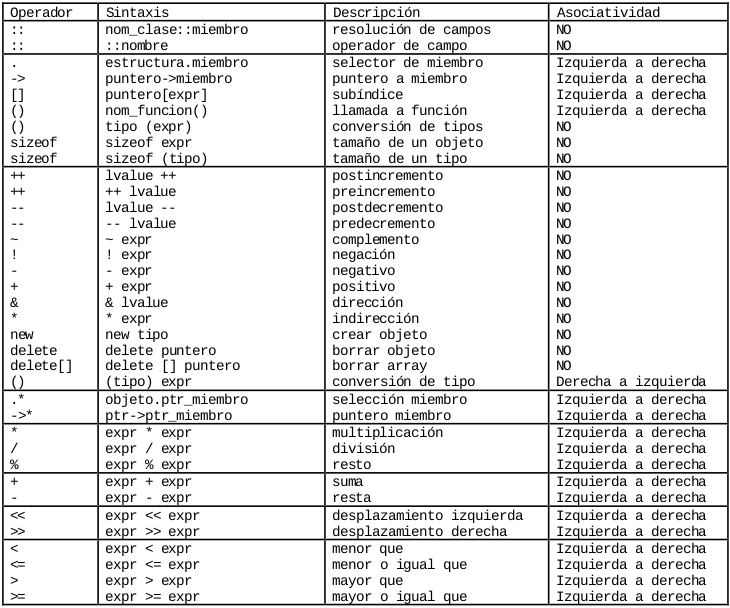

Para terminar con los operadores indicaremos que el orden de evaluación de los operandos no está predefinido, excepto en los casos siguientes:
a || b -- Si se cumple a no se evalúa b
a && b -- Si no se cumple a no se evalúa b
, -- La coma evalúa de izquierda a derecha
a ? b : c -- Si se cumple a se evalúa b, sino se evalúa c
ESTRUCTURAS DE CONTROL
El C++, como todo lenguaje de programación basado en la algorítmica, posee una serie de estructuras de control para gobernar el flujo de los programas. Aquí estudiaremos las estructuras de control de la misma manera que las vimos en el bloque anterior, es decir, separando entre estructuras condicionales o de selección, de repetición y de salto.
Antes de comenzar debemos recordar que la evaluación de una condición producirá como resultado un cero si es falsa y un número cualquiera distinto de cero si es cierta, este hecho es importante a la hora de leer los programas, ya que una operación matemática, por ejemplo, es una condición válida en una estructura de control.
Estructuras de selección
Dentro de las estructuras de selección encontramos dos modelos en el C++, las de condición simple (sentencias if else) y las de condición múltiple (switch). A continuación estudiaremos ambos tipos de sentencias.
La sentencia if
Se emplea para elegir en función de una condición. Su sintaxis es:
if (expresión)
sentencia 1
else
sentencia 2
Los paréntesis de la expresión a evaluar son obligatorios, la sentencia 1 puede ser una sola instrucción (que no necesita ir entre llaves) o un bloque de instrucciones (entre llaves pero sin punto y coma después de cerrar). El else es opcional, cuando aparece determina las acciones a tomar si la expresión es falsa.
El único problema que puede surgir con estas sentencias es el anidamiento de if y else: Cada else se empareja con el if más cercano:
if (expr1)
if (expr2)
acción 1
else // este else corresponde al if de expr 2 acción 2
else // este corresponde al if de expr1 acción 3
Para diferenciar bien unas expresiones de otras (el anidamiento), es recomendable tabular
correctamente y hacer buen uso de las llaves:
if (expr1) {
if (expr2)
acción 1
} // Notar que la llave no lleva punto y coma después, si lo pusiéramos
// habríamos terminado la sentencia y el else se quedaría suelto
else // Este else corresponde al if de expr1 acción 3
if (e1)
a1
else if (e2)
a2
else if (e3)
a3
...
else
an
La sentencia switch
Esta sentencia nos permite seleccionar en función de condiciones múltiples. Su sintaxis es:
switch (expresión) {
case valor_1: sentencia 11;
sentencia 12;
...
sentencia 1n;
break;
case valor_2: sentencia 21;
sentencia 22;
...
sentencia 2m;
break;
...
default:
sentencia d1;
sentencia d2;
...
sentencia dp
}
Indicaremos que si queremos hacer lo mismo para distintos valores podemos escribir los case seguidos sin poner break en ninguno de ellos y se ejecutará lo mismo para todos ellos.
Ejemplo:
void main() {
int i;
cin >> i;
switch (i) {
case 0:
case 2:
case 4:
case 6:
case 8:
cout << " El número " << i << " es par\n";
break;
case 1:
case 3:
case 5:
case 7:
case 9:
cout << " El número " << i << " es impar\n";
break;
default:
cout << " El número " << i << " no está reconocido\n";
}
}
Dentro de las estructuras de repetición diferenciábamos 3 tipos: con condición inicial, con condición final y con contador.
La sentencia do-while
Es una estructura de repetición con condición final. Su sintaxis es:
do
sentencia
while (expresión);
La sentencia while
Es una estructura de repetición con condición inicial. Su sintaxis es:
while (expresión)
sentencia
El funcionamiento es simple evaluamos la expresión y si es cierta ejecutamos la sentencia y volvemos a evaluar, si es falsa salimos.
La sentencia for
Aunque en la mayoría de los lenguajes la sentencia for es una estructura de repetición con contador, en C++ es muy similar a un while pero con características similares. Su sintaxis es:
for (expr1; expr2; expr3)
sentencia
Que es equivalente a:
expr1
while (expr2) {
sentencia
expr3
}
En el siguiente ejemplo veremos como esto se puede interpretar fácilmente como una repetición con contador:
int i;
...
for (i=0; i<10; i++) {
cout << " Voy por la vuelta " << i << endl;
}
Hay que indicar que no es necesario poner ninguna de las expresiones en un for , la primera y tercera expresión son realmente sentencias ejecutables, por lo que no importa si las ponemos dentro o fuera del for , pero si no ponemos la segunda el compilador asume que la condición es verdadera y ejecuta un bucle infinito.
Por último diremos que una característica interesante de esta estructura es que los índices no modifican su valor al salir del bucle, por lo que se pueden utilizar después con el valor que les ha hecho salir del bucle.
Estructuras de salto
El C++ pretende ser un lenguaje eficiente, por lo que nos da la posibilidad de romper la secuencia de los algoritmos de una forma rápida, sin necesidad de testear infinitas variables para salir de un bucle. Disponemos de varias sentencias de ruptura de secuencia que se listan a continuación.
La sentencia break
Es una sentencia muy útil, se emplea para salir de los bucles ( do-while , while y for ) o de un switch . De cualquier forma esta sentencia sólo sale del bucle o switch más interior, si tenemos varios bucles anidados sólo salimos de aquel que ejecuta el break.
La sentencia continue
Esta sentencia se emplea para saltar directamente a evaluar la condición de un bucle desde cualquier punto de su interior. Esto es útil cuando sabemos que después de una sentencia no vamos a hacer nada más en esa iteración.
Hay que señalar que en los for lo que hace es saltar a la expresión 3 y luego evaluar la expresión 2
La sentencia goto
Sentencia maldita de la programación, es el salto incondicional. Para emplearla basta definir una etiqueta en cualquier punto del programa (un identificador seguido de dos puntos) y escribir goto etiqueta.
Ejemplo:
for (;;) {
do {
do {
if (terminado)
goto OUT;
} while (...);
} while (...);
}
OUT : cout << "He salido" << endl;
La sentencia return
Esta sentencia se emplea en las funciones, para retornar un valor. En el punto en el que aparece el return la función termina y devuelve el valor. Si una función no devuelve nada podemos poner return sin parámetros para terminar (si no lo ponemos la función retorna al terminar su bloque de sentencias).
Ejemplo:
int min (int a, int b) {
if (a
return b; // si no hemos salido antes b es el mínimo.
// si pusiéramos más sentencias nunca se ejecutarían
}